Five frontier models, five different superpowers. After running them side by side on real campaigns for six months, here's which one I open for which marketing job — and the brand-safety landmine that makes Grok-Imagine unusable for most brands.
A 3-sub-agent competitive intel pipeline that produces an 8-page PDF brief every Friday at 6am — no human reads a single competitor page in between. The parent Claude agent dispatches a site-watcher, an ad-watcher, and a social-watcher, each returns a strict JSON schema, the parent synthesizes everything into a Markdown brief that Pandoc renders to PDF. The parent prompt, the three JSON contracts, the PDF template, and the failure modes that have actually cost me a brief.
A 0-100 pre-publish scorecard that scores any post on E-E-A-T, Depth, Freshness, and Structure (25 each), with a single Claude prompt that does all four in one pass plus a remediation list. The 75/100 + no-dimension-below-16 publish gate, the batch-of-10 audit workflow, and the hard reason a rubric beats vibes-based editing when you have 200+ posts and staff turnover.
Most LinkedIn polls are engagement bait — votes roll in, authority stays at zero. The fix: 20 polls across 4 categories that surface buyer signals, validate positioning, and feed next month's content. Pricing anchors, stack discovery, painpoint priority, belief tests — plus the Claude prompt and the 2-week rule I never break.
A time-blocked 6-hour workflow that builds 75 fully-formed Meta ads in a single day — 3 hooks, 5 visuals, 5 CTAs — uploads them as one Advantage+ campaign, and lets Meta's algorithm kill 60-65 of them in 72 hours so you can read the winners in one week instead of one quarter.
Hundreds of sites already mention your brand by name. Almost none of them link to you. I pull 200 unlinked mentions a week from Ahrefs Content Explorer, let Claude triage + draft a personalized 3-sentence email for each, and ship 40 new backlinks a month without writing a single new piece of content.
A single-subreddit Claude agent that reads EVERY new post in r/YourNiche, scores it on a DM-worthiness rubric (intent weighted 2x, threshold 24), and emails 1-3 a day worth a personal DM — with the rubric, the workflow, the etiquette rules that keep your account from being shadowbanned, and a case study: an SEO consultant ran this 90 days, sent 180 DMs at a 38% reply rate, closed 6 engagements at $4k-$12k for $46k of pipeline on a $14/month stack.
A 1-hour batch workflow to ship a 3-bullet TL;DR box to 50 old posts using sitemap scraping, a strict Claude rubric, and a JSON paste-in. The highest-leverage content refresh you can ship this week.
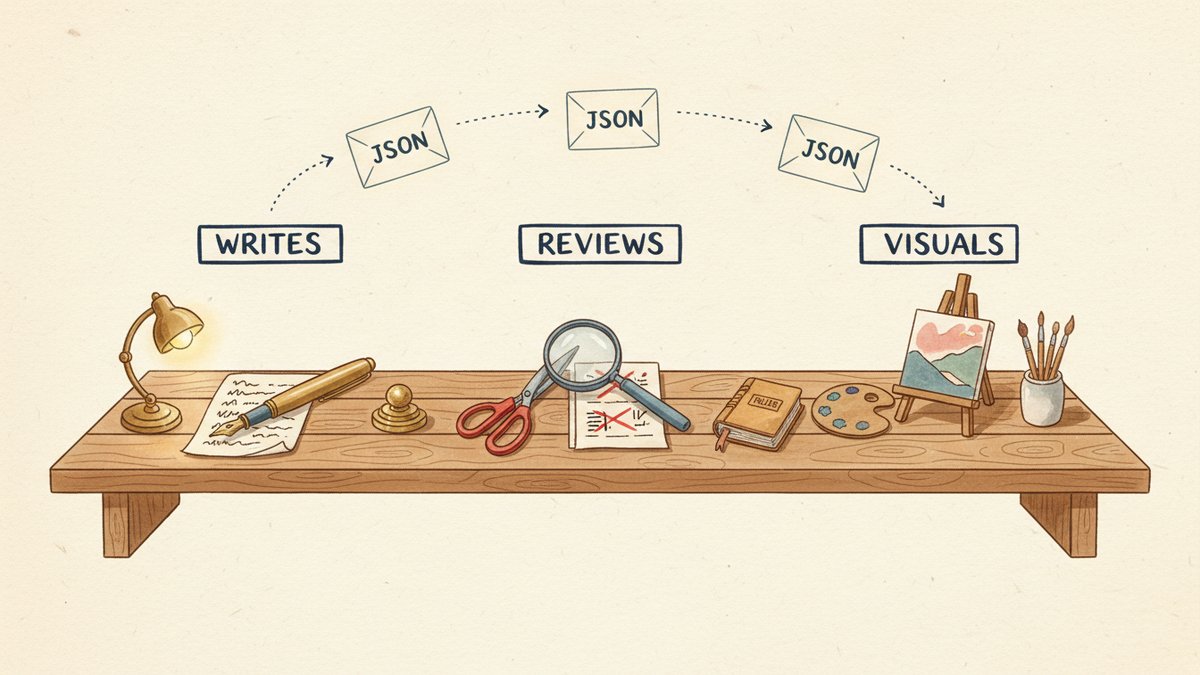
A production 3-model content pipeline where each AI does only what it is actually best at: ChatGPT drafts, Claude reviews, GPT-Image generates visuals. The actual hand-off prompts, the JSON contract between stages, the $0.41 / 18-minute cost and timing comparison vs single-model, and the model-identity-confusion failure mode that cost me a published post.
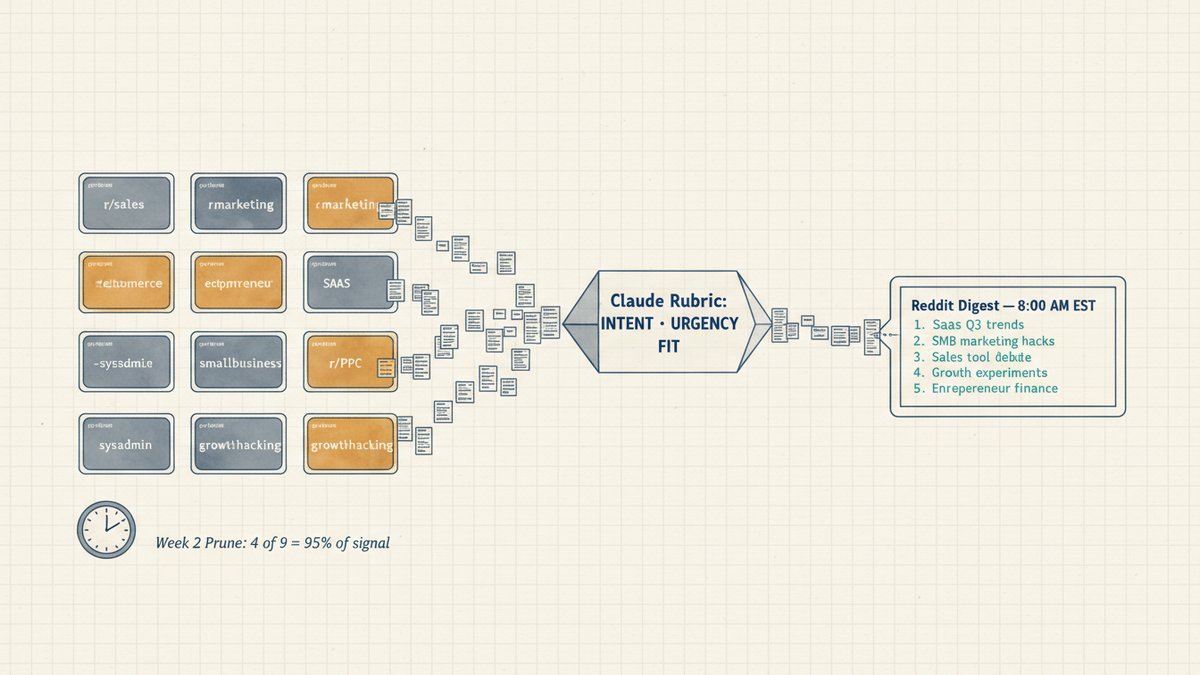
An n8n + Claude Haiku 4.5 agent that watches 9 subreddits, scores every post on a 3-axis rubric (intent, urgency, fit), and posts a top-5 daily digest to Slack — with the verbatim Claude prompt, the 9-sub shortlist, the cost math, and the week-2 finding that pruned it down to 4 subs for a +120% signal lift.
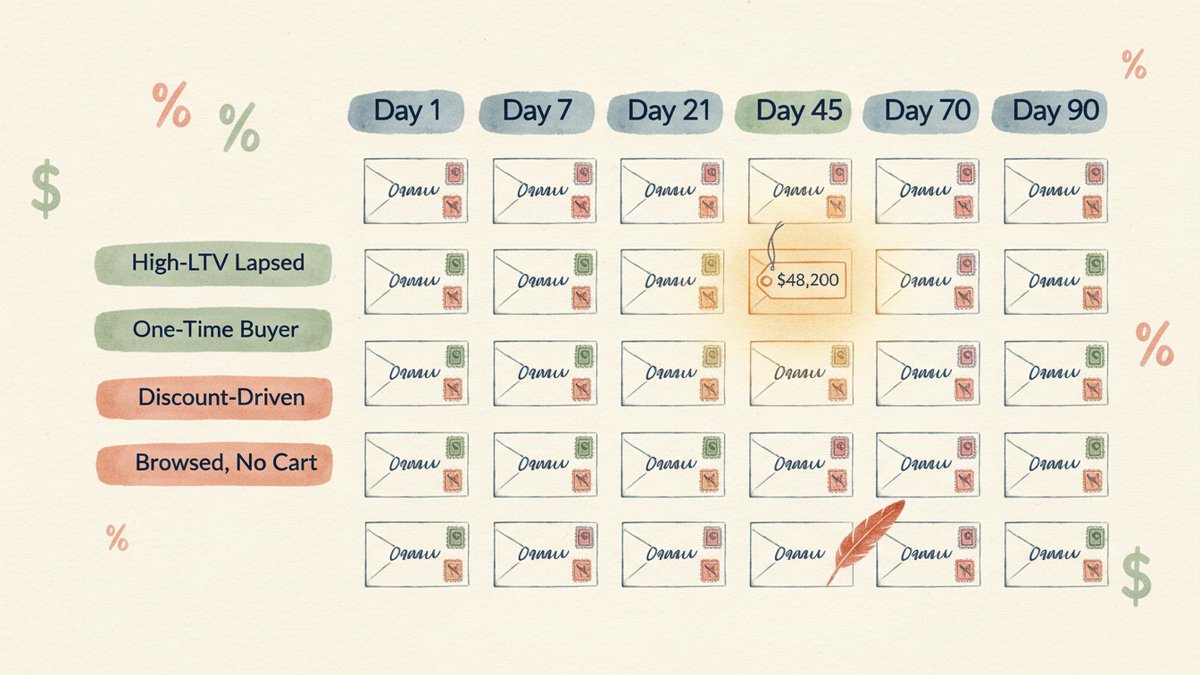
A 24-message winback matrix — 4 segments × 6 emails — for buyers who haven't purchased in 60-90+ days. Includes the Klaviyo segment conditions, the cadence, the Claude copy prompt, and the $48,200 case study.
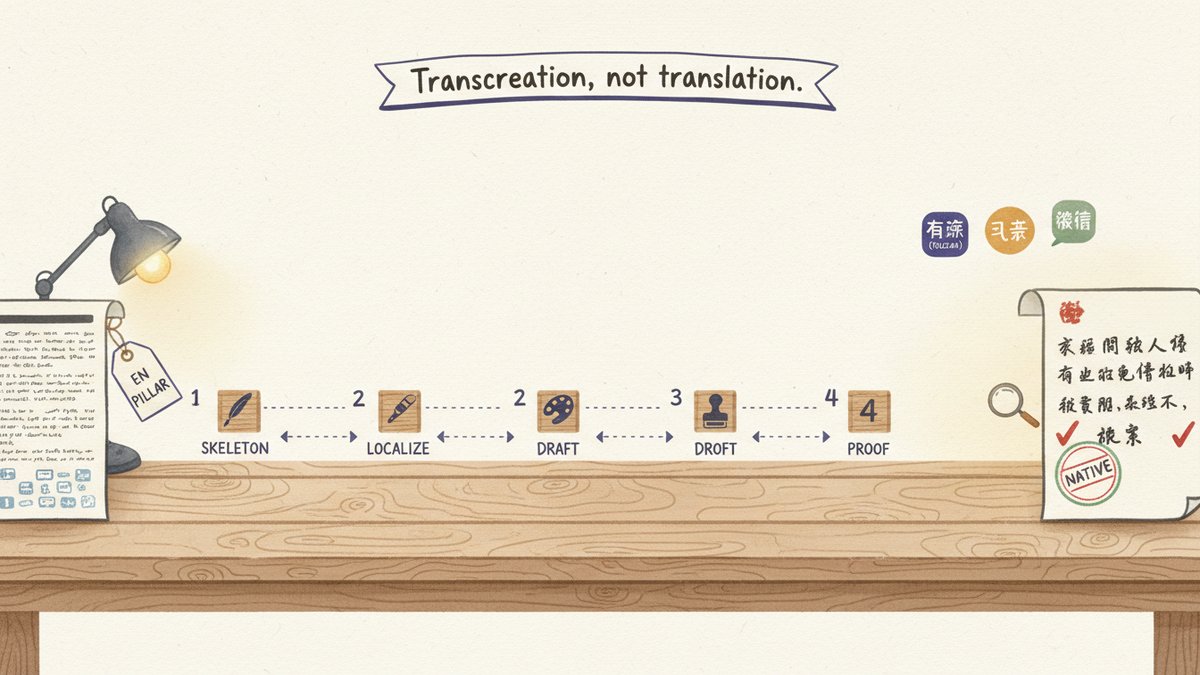
Most 'translated' content fails in China not because of vocabulary — it fails because the examples don't translate. A 4-step EN-to-zh pipeline that turns an English pillar post into a zh version that reads like it was written there, with the actual prompt, a swaps table, and a before/after.