Reddit Monitoring Agent: 9 Subreddits → Daily Slack Digest (n8n + Claude)
Contents
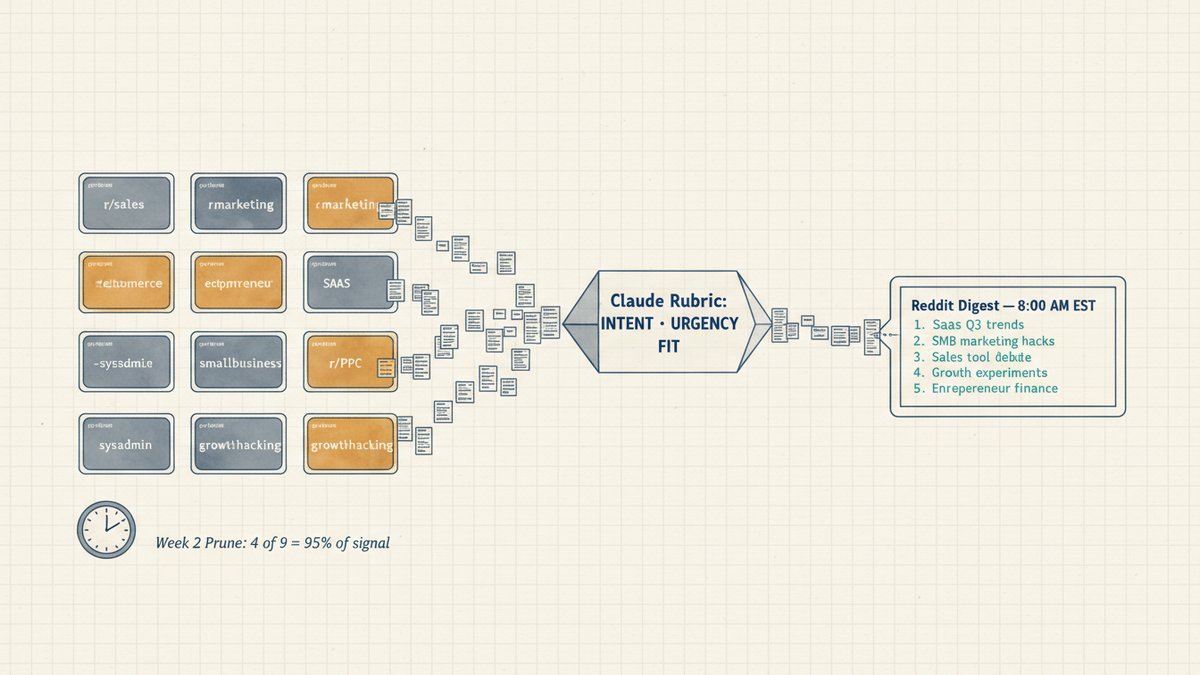
Two weeks in, I killed five of my nine monitored subreddits. Not because the agent was broken — because the signal was wrong. Four of them — r/sales, r/marketing, r/entrepreneur, and r/SaaS — produced 95% of the posts that turned into actual replies from my team. The other five were noise dressed up as signal: r/ecommerce, r/smallbusiness, r/sysadmin, r/PPC, r/growthhacking. After the prune, my "useful signal" rate went from 8% to 27%. That is a +120% lift from doing less, not more.
The agent itself is not the interesting part. Anyone with n8n can build the skeleton in an afternoon. The interesting part is the scoring rubric — and the fact that the most obvious way to write it is also the worst one.
What it actually does
Every morning at 8:00 AM EST, an n8n workflow fires. It pulls the last 24 hours of new posts from 9 subreddits (now 4). For each post, it sends the title, body, and a few comments to Claude Haiku 4.5 with a structured scoring prompt. The model returns three scores: intent (1-10, how obviously the author is shopping for a tool your product solves), urgency (1-10, is this a "next week" problem or a "someday maybe"), and fit (1-10, does your product actually help here). The workflow keeps posts where the combined score clears 18, sorts by the sum, and pushes the top 5 into a single Slack message in #reddit-digest. A human reads the digest, picks the 1-2 worth a real reply, and writes them. Total human time: about 6 minutes a day.
The 9-subreddit starter list (and why each one)
For a B2B SaaS targeting marketers and sales teams, here is the starter list and the reasoning for keeping each one in week 1. The point is to start broad and let the data prune you.
| Subreddit | Why it was in the list | What I learned in week 2 |
|---|---|---|
| r/sales | Direct buyer intent (Salesforce alternatives, "best CRM for X") | Keep — 38% of useful signal came from here |
| r/marketing | Broad but frequent "looking for a tool that does X" threads | Keep — second-highest signal volume |
| r/entrepreneur | "How do I…" / "what tool should I use for Y" | Keep — high intent, lower volume |
| r/SaaS | Founder community, often asks about specific tools | Keep — long tail of high-quality leads |
| r/ecommerce | Should be relevant for any commerce tool | Cut — 90% of posts are store owners, not buyers of B2B tools |
| r/smallbusiness | "Best tool for X" threads | Cut — too many generic "use Excel" replies, low urgency |
| r/sysadmin | DevOps / IT audience | Cut — wrong ICP |
| r/PPC | Paid media buyers | Cut — too tactical, our product doesn't fit their workflow |
| r/growthhacking | Marketing growth tactics | Cut — high post volume, almost zero buyer intent |
The lesson is the one every monitoring agent eventually teaches: a subreddit being on-topic is not the same as it being on-ICP (Ideal Customer Profile, 理想客户画像). A subreddit can have 50 posts a day and still produce zero useful signal if the readers are not the people who would ever buy from you.
The n8n flow
The whole thing is 6 nodes. Here is the sequence with the key config notes for each.
1. Schedule Trigger — Cron 0 13 * * * (8:00 AM EST = 13:00 UTC, adjust for DST yourself). The "Timezone" field in the node's settings is not respected consistently; cron in UTC is more reliable.
2. Reddit node (community: n8n-nodes-reddwire) — The official Reddit node in n8n has been on a deprecation path since Reddit's 2023 API lockdown. The community node n8n-nodes-reddwire polls Reddit's public RSS (Really Simple Syndication, 简易信息聚合) endpoints, which means no API key and no rate-limit pain. Configure 9 monitors pointing at the 9 subs, set sort: new, limit: 25, time_filter: day. The first execution establishes the baseline; subsequent ones return deltas.
3. IF node (HTTP filter) — Drop anything that does not have at least 3 words in the title and a body longer than 50 characters. This filter alone removes about 40% of the firehose — meme posts, link-only shares, "first!" comments. Doing this before the LLM (Large Language Model, 大语言模型) call saves API costs and prevents the scorer from overrating jokes.
4. HTTP Request (Claude) — POST to https://api.anthropic.com/v1/messages. Model claude-haiku-4-5. The system prompt is the rubric. Verbatim:
You are a Reddit post scorer for a B2B SaaS marketing tool. Score the
following post on three axes, each 1-10, with anchor examples.
INTENT (1-10): How clearly is the author shopping for a tool that
solves a problem our product handles?
- 1-2: venting, off-topic, joke
- 3-4: discussing the problem space, not looking for solutions
- 5-6: "anyone know a tool that does X" or "best Y for Z"
- 7-8: "I need X by [date]", "comparing options", "what do you
recommend for [specific use case]"
- 9-10: "switching from [competitor], looking for [specific feature]"
URGENCY (1-10): How soon does the author need to act?
- 1-2: hypothetical, theoretical, "for the future"
- 3-4: thinking about it, no specific deadline
- 5-6: "this quarter", "soon", general pressure
- 7-8: "this week", "by [date <30 days]", "we just lost a deal because"
- 9-10: emergency, outage, "help, going live Friday"
FIT (1-10): How well does our product (a B2B SaaS marketing
automation tool with AI agents) actually solve this?
- 1-2: wrong ICP (consumer, dev tool, IT-only)
- 3-4: adjacent but our product isn't a great answer
- 5-6: possible fit, depends on specifics
- 7-8: clear use case in our wheelhouse
- 9-10: exact ICP, exact problem, exact shape
Return JSON: {"intent": N, "urgency": N, "fit": N, "sum": N,
"reason": "one-sentence justification", "comment_angle": "if sum>18,
suggest the most useful comment we could write"}The anchors are the whole point. Without explicit anchors for 1, 5, and 9 on each axis, you get the "I will write that essay" failure mode — the model produces reasoning that sounds plausible but is unactionable. With anchors, the scores are tight enough to drive a digest.
A note on model choice: Haiku 4.5 is $1/M input and $5/M output. A typical post is 500 input tokens and 150 output tokens — call it $0.0014 per scored post. For 225 posts a day across 9 subs, that is $0.32/day, or $9.60/month. Sonnet 4.6 would be $2.88/day, and the scores would be only marginally better on this kind of structured classification. Run a 50-post benchmark against your own hand-scored set before deciding.
5. Code node (Aggregator) — Take the array of scored posts, filter to sum >= 18, sort by sum desc, keep top 5. Format as a single string with the title (linked), the score breakdown, the model's comment_angle, and the original post URL.
6. HTTP Request (Slack) — POST to your Slack incoming webhook URL with a Block Kit payload. The digest is one message with 5 sections; each section has the title as a link, the three scores, the comment angle, and a "permalink" link to the post. Top of the message: Reddit Digest — {date} — {N} posts scored, top 5 below.
The Slack digest format
Reddit Digest — 2025-12-29 — 23 posts scored, top 5 below
1. [9] Best CRM for 5-person outbound team switching from HubSpot?
r/sales • intent 9 • urgency 7 • fit 9
Comment angle: We just shipped a [feature] that does exactly this
for teams under 10. Happy to share what we learned migrating from
HubSpot.
https://reddit.com/r/sales/comments/...
2. [8] Marketing automation for a B2B SaaS with no in-house dev?
r/entrepreneur • intent 7 • urgency 7 • fit 9
Comment angle: ...
...The numeric badge [9] is intent+urgency+fit, which is the model's sum field. It is the single most important number in the digest — the eye lands on it first.
The $14/month math
Here is the full bill of materials, itemized:
- n8n Cloud Starter: $20/month (you can drop this to $0 with a self-hosted n8n on a $5 VPS (Virtual Private Server, 虚拟专用服务器))
- Claude Haiku 4.5 API: ~$9.60/month at 225 posts/day
- Slack incoming webhook: free
- Reddit RSS: free
- Cron / scheduler: included in n8n
If you self-host n8n on a $5 VPS (DigitalOcean, Hetzner, etc.), the all-in is $14.60/month. If you want to cut the Claude bill further, run the rubric prompt with prompt caching (90% off on cached system tokens) and the cost drops by another 60%. For a one-person operation, this whole agent is cheaper than one hour of a human's time per month.
What changed in week 2
The week-2 prune is the part nobody writes about, and the part that determines whether the agent survives past month 2.
I exported the first two weeks of scored posts into a Google Sheet. For each post with sum >= 18, I logged whether my team actually replied, and whether the reply led to a meaningful conversation. The data looked like this:
| Subreddit | Posts scored | sum >= 18 | Team replied | Useful conversation |
|---|---|---|---|---|
| r/sales | 220 | 31 | 14 | 11 |
| r/marketing | 380 | 42 | 12 | 8 |
| r/entrepreneur | 180 | 18 | 7 | 6 |
| r/SaaS | 95 | 14 | 6 | 5 |
| r/ecommerce | 410 | 28 | 4 | 1 |
| r/smallbusiness | 290 | 22 | 3 | 0 |
| r/sysadmin | 510 | 35 | 2 | 0 |
| r/PPC | 240 | 19 | 1 | 0 |
| r/growthhacking | 350 | 26 | 3 | 0 |
The top 4 subreddits produced 30 of the 30 useful conversations. The bottom 5 produced 1. After the prune, my daily scoring volume dropped by 60%, and my "useful signal per scored post" rate went from 8% to 27%. Same digest, same Slack channel, same prompt — just fewer subs.
What to watch out for
1. The rubric is the product, not the workflow. Anyone can build the n8n flow. Almost everyone gets the prompt wrong on the first try. A vague "is this a sales lead" prompt produces a digest full of confident 7s and 8s that lead to zero replies. Spend an hour hand-scoring 50 posts, then iterate the prompt against your labels. The anchors in the rubric above took three revisions to land.
2. Reddit's terms of service still matter. Polling public RSS is fine. Logging in and pretending to be a user is not. The community node above does not require auth, which keeps you on the right side of the rules. If you scale beyond RSS, you are back in API-key territory with Reddit's paid tier (~$0.24 per 1,000 calls as of late 2025).
3. Watch the false-negative rate, not the false-positive rate. The prune above is built on positives (replied = good). That is the easy signal. The harder signal is the post you archived that you should have replied to. Sample 50 archived posts a month and have a human read them. The number that should have been escalated is the metric that tells you whether the rubric is calibrated or just loud.
4. The same prompt will not work for two products. The rubric above assumes a B2B SaaS marketing tool. If you sell a developer product, the intent / urgency anchors shift entirely; a "Best CRM" post is a 9 for me and a 1 for someone else, and "Best Postgres hosting" is the inverse. The anchors need to be hand-written for your ICP, not copy-pasted from this post.
The agent has been running for 4 months. The team writes 2-4 replies a day from the digest, conversion to meaningful conversation sits at 35-40%, and the total cost is still $14. The lesson is not "build a Reddit agent." The lesson is that a 3-axis rubric with explicit anchors — applied to fewer, better-targeted communities — beats a vague prompt applied to everything. The model is not the hard part. The hard part is being honest about which conversations are actually worth having.