Custom GPT for Brand Compliance: Catch Violations Pre-Publish
Last quarter, an in-house team almost pushed a $40K campaign — until someone noticed the new product page claimed "FDA-approved" when it should have said "FDA-cleared." Legal caught it, the launch slipped a week, the team spent a weekend rewriting copy. The guidelines were right there in the wiki. Nobody checked. That is the gap a Custom GPT closes.
A Custom GPT trained on your brand guidelines doc doesn't have to "know" — it just has to be the one piece of software that runs every draft through the same rule set before it ships. Here's the 30-minute build I use.
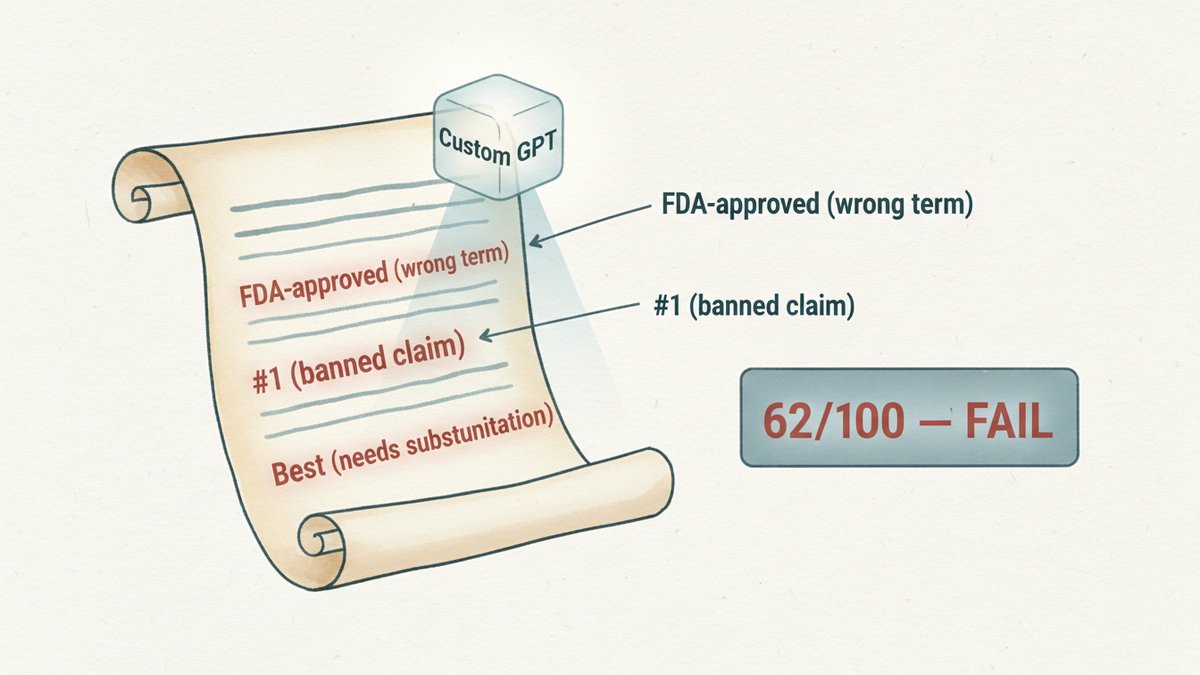
Step 1 — Dump the rule doc into Knowledge. Start with the actual brand guidelines file — the one currently gathering dust on the company drive. PDF, Google Doc, Notion page — Custom GPT chews through any of them. Include the tone of voice (with examples, not just adjectives — "warm but not soft, confident but not boastful" beats "professional"), the banned words and phrases (both industry-specific and house-style), the claims policy (which words need substantiation, which require legal sign-off, which are flat-out forbidden — "best," "#1," "guaranteed," "FDA-approved"), the legal disclaimer requirements (where they go, exact wording, when they change), and the channel-specific rules (what's allowed on Meta vs. LinkedIn vs. email). If you have regulator filings (FTC, GDPR, FDA, financial), drop them in too. The model treats them as reference, not gospel.
Step 2 — Write instructions that force a verdict, not a vibe. The default Custom GPT prompt tells it to "check tone and flag issues." It will, but it'll also be polite about it. Override that. In the instructions, always require: a 0-100 compliance score across 4-5 dimensions (tone, claims, banned words, legal, channel fit), line-by-line flags citing the exact rule ("Line 3, sentence 2: 'best-in-class' — violates Claims Policy §2.1"), a fix suggestion per violation, and a simple pass/fail at the end (do not soften this). Telling it to give a score changes the behavior. Models hesitate more when a number is on the line.
Step 3 — Wire it into the actual workflow. The Custom GPT is useless if it's buried in someone's bookmarks. Pick the moment of friction — usually right before a draft is scheduled or a campaign is uploaded — and make the GPT the gate. Three options, in order of how much work I want to do: paste a draft into the GPT, get the score, paste the fix back; use the GPT's API to auto-check Notion or Google Docs; or pipe it through Make or Zapier so a draft gets scored the moment it lands in the review queue. I've used all three. Option 1 sounds lazy, but it's the one people actually run daily.
Step 4 — Treat the scorecard as a living doc. Every time a violation slips through — a banned phrase the GPT didn't catch, a legal disclaimer that landed in the wrong place — add it to the Knowledge file and update the instructions. The model gets sharper with every miss. Audit monthly: pick 10 random published assets, score them in the GPT, see where it disagrees with the human reviewer. That's the next round of training data.
This is not a substitute for legal. The Custom GPT catches only what it's told to catch. Anything outside its rule set still needs a human in the loop. Think of it as a tire-pressure light: it tells you something's off; you still take the car to the mechanic.
The 30-minute build, end to end: 10 minutes to clean up the brand guidelines doc and export as PDF; 10 minutes to drop it into Knowledge and write the verdict-style instructions; 5 minutes to test with 3-5 real drafts and refine the rules; 5 minutes to share with the team and document the workflow. After that, every draft that ships past your team goes through the same gate.