自定义 GPT 守住品牌合规:发布前先把违规拦下来
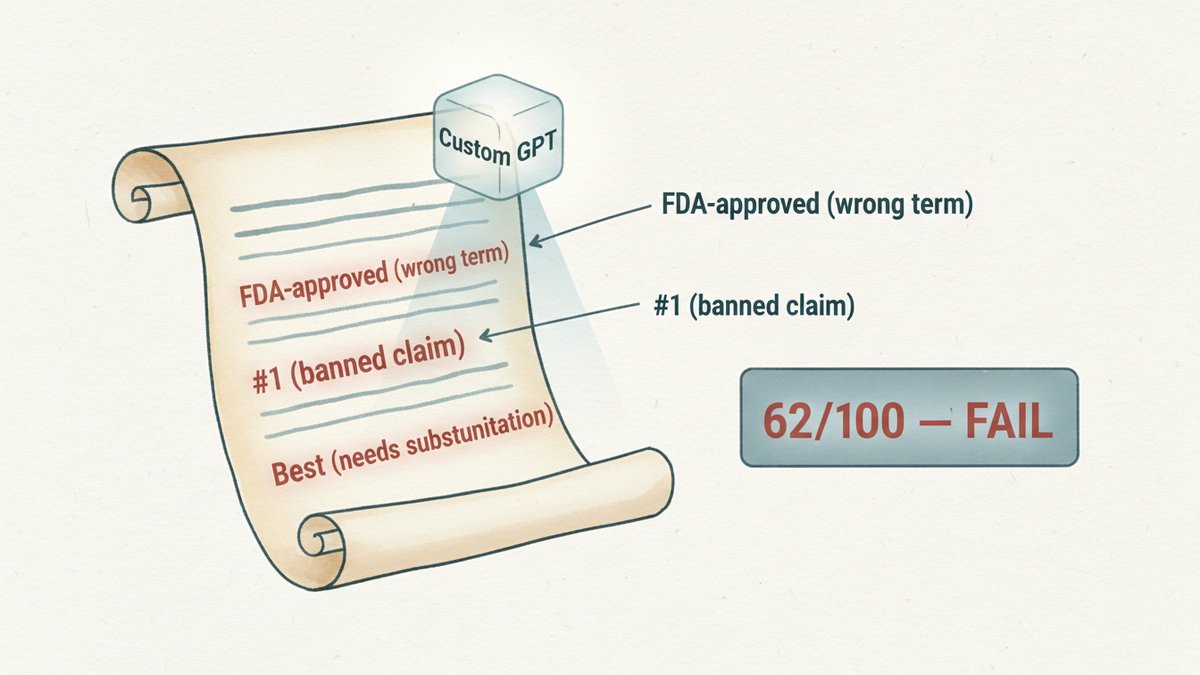
上季度,一个内部团队差点把一个 4 万美金的方案推上线——直到有人发现新上的产品页写的是"FDA-approved"(FDA 批准),而正确说法是"FDA-cleared"(FDA 备案)。法务拦下来,上线推迟一周,团队花了一个周末重写文案。品牌规范明明就放在 wiki 里,就是没人查。这就是 Custom GPT 要堵住的漏洞。
一个训练过品牌规范文档的 Custom GPT,不一定"懂"什么,它只要在内容发布前把每篇稿子都过一遍同一套规则就行。这是我用的 30 分钟搭建流程。
第一步:把规则文档丢进 Knowledge(知识库)。 从你公司网盘上那份正在吃灰的品牌规范文件开始。PDF、Google Doc、Notion 页面都行,Custom GPT 都能消化。要包括:语气和口吻(要有例子,别只写形容词——"温暖但不软弱、自信但不吹牛"比"专业"有用得多);禁用词和禁用短语(行业特定的,加上公司内部风格的);宣传话术政策(哪些词需要举证、哪些需要法务签字、哪些直接禁掉——"best""#1""guaranteed""FDA-approved" 都属于这类);法律免责声明的要求(放在哪儿、原文怎么写、什么场景下要换措辞);还有渠道特定规则(Meta、LinkedIn、邮件分别能用什么、不能用什么)。如果手上有监管机构的文件(FTC、GDPR、FDA、金融监管),也丢进去。模型会把它当参考资料,不当真理。
第二步:在 Instructions 里强制它给结论,别让它打太极。 默认的 Custom GPT 提示词只会告诉它"检查语气和标记问题"。它会做,但会很客气。把这一点压过去。在 Instructions 里要求它每次必须返回:一个 0-100 的合规分,拆成 4-5 个维度(语气、宣传话术、禁用词、法律、渠道适配);逐行标黄,引用具体规则("第 3 段第 2 句:'best-in-class'——违反宣传话术政策 §2.1");每一项违规给一个修改建议;末尾一个简单的 pass/fail(不要软化这个)。让模型给打分,行为会变。数字摆在桌上,它犹豫得更多。
第三步:接到真实工作流里。 Custom GPT 埋在谁的浏览器收藏夹里都没用。找一个有摩擦的瞬间——通常是稿子定档、方案上传之前——让 GPT 当那个闸门。三个选项,按我愿意花多少力气排:把稿子粘进 GPT,拿到分,再把改完的粘回去;用 GPT 的 API,自动扫 Notion 或 Google Doc;或者接到 Make 或 Zapier 上,稿子一进审核队列就自动跑分。三种我都用过。第一种看起来最偷懒,但它才是大家每天真的会用的。
第四步:把这份评分表当活文档维护。 每次有漏网的违规——GPT 没抓到的禁用词、放错位置的法律免责——都补到 Knowledge 里,再更新 Instructions。模型每次漏判都会更准。每月做一次审计:随机抽 10 个已发布的素材,丢给 GPT 打分,看它和真人审核的意见哪里不一样。那就是下一轮的训练数据。
它不能替代法务。Custom GPT 只抓你告诉它要抓的东西。规则集外的东西还是要有人兜底。把它当成胎压报警灯:告诉你有问题,但你还是得把车开去修。
30 分钟搭建,完整流程:10 分钟把品牌规范文档清理一下,导出 PDF;10 分钟丢进 Knowledge,写好要结论的 Instructions;5 分钟拿 3-5 篇真实稿子试跑,微调规则;5 分钟发给团队,把流程用两行字写下来。之后,每个从你团队手上发出去的稿子都过同一道闸。