Make.com 4-Agent Lead Routing: Enrich, Score, Route, Notify with Gemini as the Brain
Contents
3:47 AM. My phone lit up with a Slack notification: 412 new form submissions in the last four hours, all from a webinar campaign. By the time I was pouring coffee at 7 AM, the sales team's channel looked like a complaint box — the SDRs (Sales Development Representatives, 销售开发代表) had triaged them by hand, marked 73 as "junk" using a regex on the company name, and missed two of the three enterprise leads in the batch. The third enterprise lead got routed to a junior rep whose calendar was full for the week.
That was the morning I stopped scoring leads with regex and rebuilt the pipeline around four small agents. It has been running for fourteen months. It costs about $11 a month in API (API, Application Programming Interface, 应用程序接口) and Make (the platform formerly called Integromat) operations for a typical 1,200 leads/week volume. This post is the actual scenario.
Why four agents and not one big prompt
A single mega-prompt that does enrichment, scoring, routing, and notification in one go is tempting. I built it. It worked on 8 out of 10 leads and silently hallucinated company sizes on the other 2 — the model was guessing because the prompt had no room to admit "I don't know." Worse, when something went wrong, I could not tell which step was the broken one.
Four small agents fix three things at once:
- Composability — I can swap the enrichment vendor (Apollo, Clearbit, Dropcontact) without touching scoring. Last quarter I moved from Clearbit to Apollo because Clearbit changed their credit pricing. The other three agents did not change.
- Debuggability — Every agent logs its own input bundle and output bundle. When the SDR team reports a misrouted lead, I open the run history for that lead, see each agent's JSON (JavaScript Object Notation, 一种结构化数据格式), and find the bad step in under a minute. With a single mega-prompt, every failure is a prompt-engineering problem.
- Cost and latency — Routing is a cheap rule. Scoring is the expensive LLM call. By splitting them, 70% of leads skip the LLM scoring step entirely (e.g., anything from a free-mail domain with a generic message body goes straight to a nurture campaign).
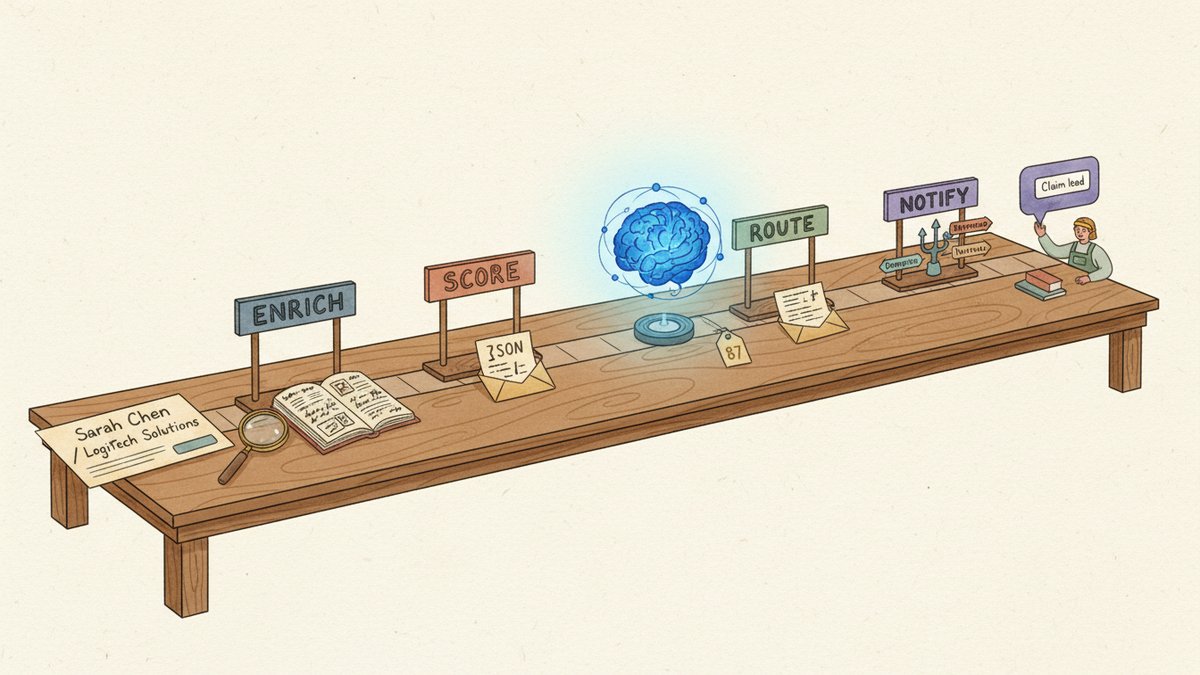
The architecture, top to bottom
The whole pipeline is one Make.com scenario. Six modules, four of which are the named "agents" — each agent is a HTTP → Make a Request module calling the Gemini API (Google's LLM family, currently gemini-2.5-flash for cheap calls and gemini-2.5-pro for the scoring brain) with a structured prompt and a JSON schema in the response.
- Webhook trigger — Typeform or Webflow form posts to Make on submission. (1 operation)
- Agent 1: Enrichment — Apollo API for company firmographics (size, industry, funding), then Gemini extracts a one-line "what this company does" from the company's homepage HTML. (2 operations)
- Filter module — if the lead is from a free-mail domain AND has fewer than 20 words in the message body, branch to nurture. This kills the long tail of bot and "just curious" submissions before any LLM cost.
- Agent 2: Scoring — Gemini reads the enriched bundle plus the original message, returns a structured JSON with
score(0-100),intent(one of: buy, evaluate, lurk, vendor, spam), andreasoning(1-2 sentences). (1 operation) - Agent 3: Routing — pure rule module, no LLM. If
score >= 75andintent in [buy, evaluate], route to the enterprise round-robin. Ifscore 50-74, route to the SMB (Small and Medium Business, 中小型企业) queue. Ifscore < 50andintent == lurk, add to a newsletter nurture. Everything else gets a polite "we'll be in touch" auto-reply. - Agent 4: Notification — a single Slack message to the assigned rep's channel, plus an email if score is 75+. The Slack message uses Slack's Block Kit with a single button "Claim lead" that calls back to Make and updates the CRM (HubSpot in my case) owner field.
End-to-end latency for the median lead: 38 seconds. End-to-end cost per lead: $0.009. Of that, $0.0066 is the Gemini scoring call; the rest is enrichment and Make operations.
What you need before you build
| Component | Why |
|---|---|
| Make.com Core plan ($10.59/mo) | Free tier's 1,000 ops is gone by week two at this volume. Core's 10,000 ops covers 1,500 leads/month with headroom |
| Gemini API key from Google AI Studio | Use gemini-2.5-flash for Agent 1 (extraction is cheap) and gemini-2.5-pro for Agent 2 (scoring needs reasoning) |
| Apollo API key on a Growth plan | Free tier credits run out at 50 leads/month. The Growth plan is the realistic floor |
| A CRM with an open API | HubSpot, Pipedrive, Salesforce all work. The Make CRM module handles auth in 2 clicks |
| A Slack workspace | For the rep notifications. Email is fine as a backup but reps miss email |
The build itself takes about three hours the first time. After that, each agent's prompt is a 5-minute edit. I have rebuilt the scoring agent's prompt four times in fourteen months as I learned what signals actually predict SQL (Sales Qualified Lead, 销售合格线索) conversion.
The four agents, in detail
Agent 1: Enrichment (Apollo + Gemini extraction)
The Apollo People/Company Enrichment API returns structured firmographics — industry, employee count, estimated revenue, tech stack, recent funding events. That covers 60% of what I need. The remaining 40% — what does this company actually do, in plain language — comes from a Gemini call that takes the company's homepage HTML, strips it to text, and returns one sentence.
The prompt is short on purpose. Long prompts cost more and the model tries harder to be clever than to be right.
System: You are a B2B (Business to Business, 企业对企业) research assistant. Read the homepage text and produce exactly one sentence describing what the company does, who it serves, and how it makes money. If the text is too thin to answer, return the literal string "INSUFFICIENT". User:
{{homepage_text}}Response schema:{ "summary": string }
The INSUFFICIENT literal is a guard. When Agent 2 sees it, it downgrades intent to lurk regardless of the message body. I learned this the hard way: one Apollo enrichment returned a real company's homepage that was actually a parking page, and Gemini cheerfully hallucinated a SaaS (Software as a Service, 软件即服务) summary. The literal-string guard catches the failure.
Agent 2: Scoring (the brain)
This is the only agent that actually uses Gemini Pro. It receives the full bundle: Apollo firmographics, Agent 1's one-sentence summary, the original form fields, and the message body. It returns a structured JSON.
System: You score inbound B2B leads for a B2B SaaS company. Score from 0 to 100 where 100 is "this is the buyer with budget and timeline." Return JSON with
score(integer 0-100),intent(one of: buy, evaluate, lurk, vendor, spam), andreasoning(1-2 sentences referencing the actual signals you used). Do not invent company details — if the bundle is missing something, lower the score and say why. User:{{enriched_bundle}}Response schema:{"score": int, "intent": enum, "reasoning": string}
Two things to note:
First, the response schema is enforced. Gemini's structured output mode rejects any response that does not parse to the schema. This is what stops the model from "helpfully" returning a paragraph instead of a JSON. The Make module is HTTP → Make a Request with Response type: JSON and a Data structure validator.
Second, the prompt explicitly tells the model it can lower the score. Without that line, the model tended to score everything 60-90 because it could not tell which fields were missing. With the line, "the email is from a personal Gmail, no Apollo data, and the message body says 'just curious' — score 22" becomes a normal output.
Agent 3: Routing (no LLM, pure rules)
This is the most-boring module in the scenario and that's the point. Once you have structured output from Agent 2, you do not need another LLM to make a routing decision. A Router module with three branches handles 95% of cases:
score >= 75 AND intent in [buy, evaluate]→ enterprise round-robinscore 50-74→ SMB queuescore 30-49 OR intent == lurk→ newsletter nurture (HubSpot list add)- everything else → auto-reply "thanks, we'll be in touch within 2 business days"
The remaining 5% — high scores from leads in industries the sales team does not serve — fall through to a manual triage queue with a daily Slack digest. The SDR manager reviews them on Friday morning. This is the deliberate human-in-the-loop point.
Agent 4: Notification (Slack Block Kit + HubSpot)
Two paths. Score under 75: just a Slack message. Score 75+: Slack plus an email with the full enriched bundle inline, because the enterprise reps prefer to read the lead's context in email before claiming in Slack.
The Slack message looks like this in Block Kit (simplified):
New lead: Sarah Chen, VP Engineering at LogiTech Solutions Score: 87 | Intent: buy | Source: Webinar Q1 "Looking for a tool to replace our current vendor by end of Q2..." Enriched: 240 employees, Series B, fintech vertical
[Claim lead][View in HubSpot][Mark as nurture]
The Claim lead button is a Slack interactivity webhook that calls back to Make. Make updates the HubSpot owner field, sets the lead status to Working, and posts a confirmation message in the same thread. The full claim-to-CRM roundtrip takes about 6 seconds.
Three things that break
After fourteen months in production, the same three failures keep showing up. I have guards for all of them now.
1. Apollo returns stale data. Apollo's "estimated employee count" is a 6-month-old snapshot for about 8% of companies. Agent 1 happily passes it through. Agent 2 reads the stale number and scores accordingly. The fix: a Make filter between Agents 1 and 2 that drops the lead to manual triage if Apollo's last_updated field is more than 90 days old. I re-enrich these in batch on Sundays.
2. The free-mail filter is too aggressive. I set the threshold at "free-mail domain AND fewer than 20 words in the message body." A surprising number of legitimate buyers — especially solo founders and early employees at seed-stage startups — write short, casual messages from Gmail. The fix: do not filter. Just score. Agent 2 is good enough at distinguishing "lurk" from "buy" that the filter is no longer pulling its weight. I removed it three months in.
3. Score drift over time. After about six months, the distribution of scores compressed. The average drifted from 60 to 70 because the prompt was rewarding certain phrases. I re-calibrated by pulling a sample of 100 leads the sales team had actually closed (won) and another 100 of closed-lost, then re-tuning the system prompt to ask Gemini to anchor against those distributions. This is not a one-time thing — I do it every quarter. The cost is one afternoon and a few hundred Gemini calls. The benefit is the score stays meaningful as your buyer profile shifts.
A reframe on what to actually build
If you take only one thing from this post, take this: do not build one big prompt that does everything. Build four small, observable, replaceable agents. The win is not the LLM. The win is that when Clearbit changes pricing next quarter, or when Gemini's structured output mode gets a parameter renamed, you can swap one agent in an afternoon and the other three keep running.
That morning with 412 unscored leads, the regex did not fail. It did exactly what regex does. The mistake was trusting a deterministic rule to do a job that needs judgment. The four-agent pipeline does not "solve" lead scoring — it makes scoring observable, swappable, and auditable. That is what production AI looks like, and it is what you actually want when the SDRs are paging you at 7 AM.