Slack /research 命令 10 分钟产出带引用的 3 段简报(n8n + Perplexity)
目录
上周我看着一位策略师在 #product 频道里花 45 分钟回答一个竞品问题。问题本身并不难——"Linear 在 Q3 changelog 里刚发了什么?"——但她必须离开 Slack,打开 Perplexity,粘贴查询词,等待,复制三个标签页的来源,切到 Claude,让它给频道写一份摘要,编辑结果,粘回 Slack,然后再和一个同事争论这些来源是不是真的。九个工具,四次上下文切换,最后的消息里没有引用链接。
我把整件事重写成了一个斜杠命令(slash command)。在任何频道里输入 /research what did Linear just ship in their Q3 changelog?,4-6 分钟后,一份带内联引用的 3 段简报会落在同一个对话里。同样的数据,不用切标签页,引用链接任何人都能点。每次查询的总成本大约 $0.08,主要是 Perplexity Sonar 调用。
只要你有 n8n 实例和 Slack workspace,你今天午饭前就能把它跑起来。下面的整条流水线齐了:webhook、Perplexity、Claude、回写 Slack 的响应,以及那个在 n8n 社区里造成 80% "跑不通" 工单的 Slack 配置。
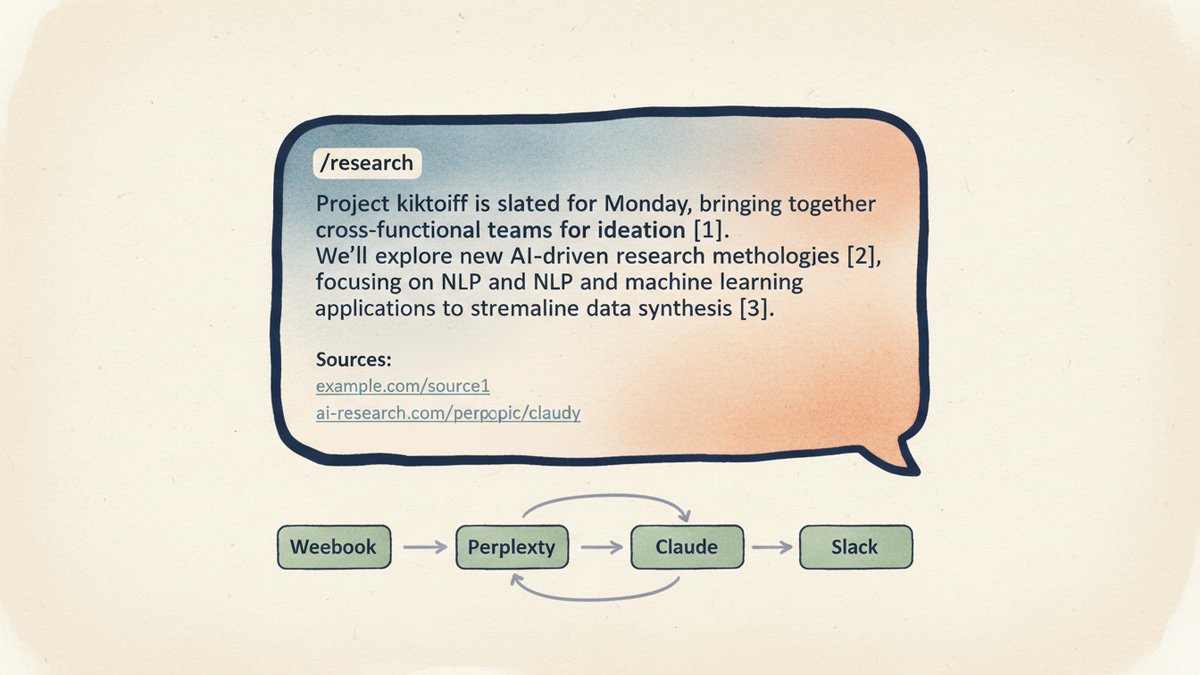
一段话讲完流水线
用户在 Slack 里输入 /research <问题>。Slack 把这个命令 POST 到一个公网 webhook URL——也就是 n8n 的 Webhook 触发节点。n8n 调用 Perplexity 的 Sonar API(Sonar 是 Perplexity 的联网检索模型——它跑一次实时搜索,写一段话,同时把来源 URL 列表一起返回给你)。Perplexity 的响应——正文加上一个 citations(引用)数组——被传给 Claude,附上一条"改写成 3 段,保留 [1][2][3] 内联标记"的指令。Claude 返回一份干净的简报,n8n 把它格式化成一条 Slack 消息——底部带上可点击的引用链接——再用 Slack 的 chat.postMessage API 贴回原频道。整个工作流只有 5 个 n8n 节点。没有状态文件,没有数据库,没有向量库。流转的只有一个会增长的 JSON 对象。
第一步 —— 创建 Slack 斜杠命令
在 Slack App 配置里,Slash Commands → Create New Command。Command: /research。Request URL: 粘贴你的 n8n webhook URL(第二步里你会拿到,可以之后再编辑)。Short Description: "Run a cited research brief in this channel." Usage Hint: <your question>。
保存命令。Basic Information → App Credentials 里你会拿到一个 Signing Secret(签名密钥)——复制下来,第二步要用。
关键配置 —— 80% "跑不通" 工单的根源: 在 Escape channels, users, and links sent to your app 选项里,全部保持默认,不要勾选 "Escape usernames"。更关键的是,确保 bot 被邀请进了执行命令的频道(/invite @YourBotName)。如果 bot 不在频道里,Slack 会以 dispatch_failed 失败,但 n8n 其实是正常收到请求的。第五步再细说。
第二步 —— 搭 n8n Webhook 触发
在 n8n 里新建一个 workflow。加一个 Webhook 节点,方法选 POST,认证选 Header Auth,header 名字写 X-Slack-Signature,值填你的签名密钥(快速搭建时你也可以在节点设置里关掉签名验证——上线前再打开)。
Respond 设为 Immediately,状态码 200,body 写 {"response_type": "ephemeral", "text": "Research started. Brief will post in this channel in 4-6 minutes."}。ephemeral 标记(Slack 的术语,指只有请求者自己能看到的消息)让用户知道事情在跑,又不会在频道里刷一条 "Workflow was started" 消息——这是 n8n 社区里第二多的吐槽。
webhook payload 里会带 text(用户的问题)、channel_id、user_id 和 response_url(Slack 提供的一个 URL,你之后可以 POST 回去把消息贴进同一个对话)。
第三步 —— 调用 Perplexity Sonar
在 Webhook 之后加一个 HTTP Request 节点。方法 POST,URL https://api.perplexity.ai/chat/completions,认证 Header Auth,header Authorization,值 Bearer {{ $env.PERPLEXITY_API_KEY }}。
Body(JSON):
json{
"model": "sonar",
"messages": [
{
"role": "system",
"content": "You are a research analyst. Answer with specific facts and numbers. Cite every non-trivial claim with [1], [2], [3] markers. Return at least 3 distinct sources from authoritative outlets."
},
{
"role": "user",
"content": "{{ $json.body.text }}"
}
]
}sonar 是 Perplexity 标准的联网检索模型。sonar-pro 在技术深度上更好,但成本大约贵 5 倍。3 段营销简报,sonar 就是合适的默认值。
注意: Perplexity 在 2025 年 4 月停止上报引用的 token 计数了,所以你看不出响应里每个来源被加权了多少。citations 数组还是完整的,但逐源的 token 分配没了。后续处理以 URL 列表为准,不要再算 token 这笔账。
第四步 —— 用 Claude 改写成 3 段
再加一个 HTTP Request 节点给 Claude。URL https://api.anthropic.com/v1/messages,header x-api-key 填你的 Anthropic 密钥,header anthropic-version: 2023-06-01。
Body:
json{
"model": "claude-3-5-sonnet-20241022",
"max_tokens": 900,
"system": "You are a senior research analyst. Take the research notes below and rewrite them as exactly 3 paragraphs. Paragraph 1: the core answer with the most important fact. Paragraph 2: supporting context, numbers, and a second perspective. Paragraph 3: what to do next, the open question, or a notable risk. Preserve every [1], [2], [3] citation marker from the source. Do not invent facts. Do not add citations that are not in the source. Do not exceed 3 paragraphs. Output only the brief, no preamble.",
"messages": [
{
"role": "user",
"content": "{{ $node['HTTP Request'].json.choices[0].message.content }}"
}
]
}Claude-3.5-Sonnet 对 3 段改写来说是杀鸡用牛刀——Haiku 十分之一的成本就能干——但 Sonnet 才是能稳定把每条引用标记对齐到正确论断的那个。想省钱的,先用 20 份简报对 Haiku 做一轮基准测试;简报这么短,失败率本来就不会高。
第五步 —— 回写到 Slack
再加一个 HTTP Request 节点。URL: https://slack.com/api/chat.postMessage。header: Authorization: Bearer {{ $env.SLACK_BOT_TOKEN }}。
Body:
json{
"channel": "{{ $node['Webhook'].json.body.channel_id }}",
"text": "{{ $node['HTTP Request1'].json.content[0].text }}",
"blocks": [
{
"type": "section",
"text": { "type": "mrkdwn", "text": "{{ $node['HTTP Request1'].json.content[0].text }}" }
},
{ "type": "divider" },
{
"type": "context",
"elements": [
{
"type": "mrkdwn",
"text": "*Sources:* {{#each $node[\"HTTP Request\"].json.citations}}<{{this}}> • {{/each}}"
}
]
}
]
}text 字段是给屏幕阅读器和通知用的兜底。blocks 字段渲染富文本消息。底部的 Sources 行才是这份简报真正有用的地方——三四个可点击的链接,没有切标签页,没有"信我"式引用。
如果消息静默失败: 最常见的原因是 bot 不在目标频道里。Slack 的 chat.postMessage 会返回 {"ok": false, "error": "not_in_channel"},但 Webhook 触发其实完全正常。两种修法:把 bot 邀请进频道(/invite @YourBotName),或者改成给请求者私聊。私有频道还需要 bot token 加上 groups:read 和 groups:write 两个 scope。
容易踩的坑
速率限制。 Perplexity 的 API tier 跟着累计消费走,不是固定的月度配额。最初几周你会落在 Tier 0 或 1,配额很宽。团队重度使用(每天 50+ 份简报)会让你往上爬 tier,每次请求的成本保持不变——但一次 bug 引发的死循环会比你预想更快烧穿你的 tier。在 n8n HTTP 节点里设一个硬上限。
简报质量只看问题质量。 模糊的问题产出模糊的简报。在频道置顶里加一行小贴士:"Tip: prefix /research with a specific company, product, or time range for tighter briefs."(提示:给 /research 加上具体公司、产品或时间范围会得到更紧的简报。)
引用能点,但不一定权威。 来源是 Perplexity 挑的。有时第一条引用是篇水博客,第三条才是 McKinsey 报告。简报读起来一模一样。如果你需要受信任的来源,给 Perplexity 调用加一个 search_domain_filter(比如限制在 .gov、.edu 和一份简短的分析师公司白名单里)。
跨调用没有记忆。 每次 /research 都是新查询。策略师问完 Linear 的问题,没法紧接着追问"那和 Notion 比呢"——必须重新问。如果团队需要这种追问,最干净的做法是再加一个斜杠命令:从 Notion 页面读上一份简报,作为上下文喂给下一次调用。工作流更大,是另一篇文章。
这个命令已经在我们团队频道里跑了六周。平均一份简报 4 分 20 秒回来,成本 $0.07 到 $0.11,被重跑过 217 次。那个 45 分钟的手工流程没了。我听到最多的后续反馈不是"怎么让它更好"——而是"手机上也能用吗"——这恰好证明了 Slack app 就是这类 agent 该待的地方。人已经在那里了。数据在另一头的 API 里等着。缺的只是一条斜杠命令。