5 步筛选法:用 Gemini 找到低竞争、高购买意图的关键词
目录
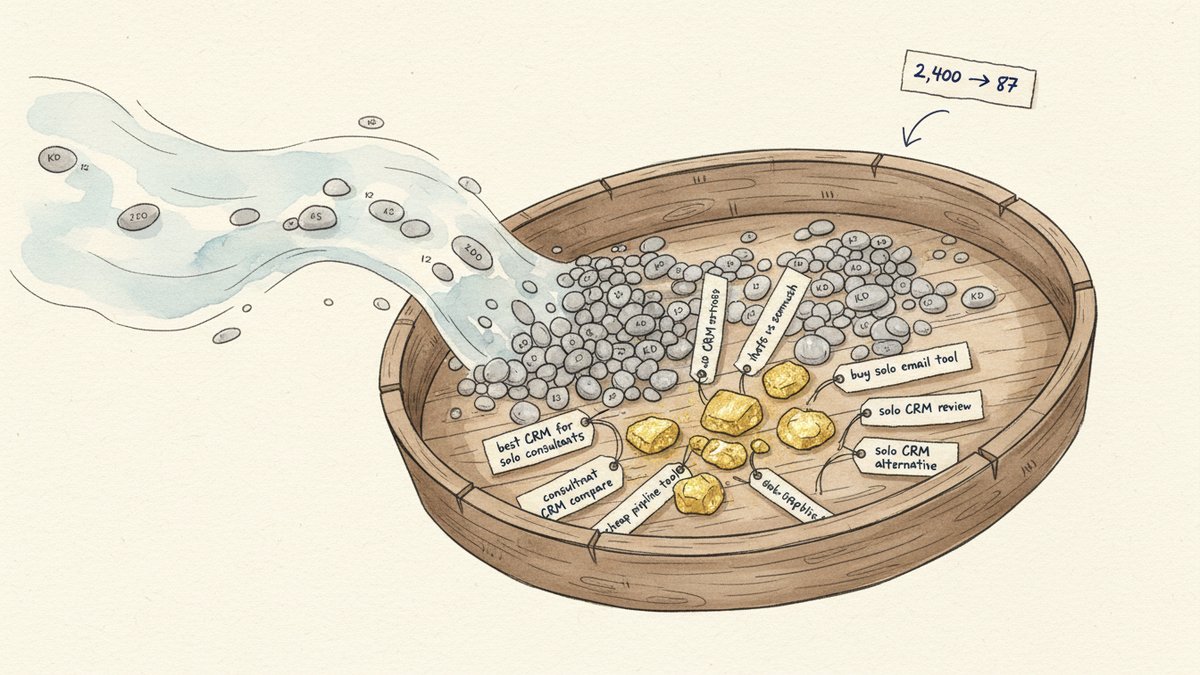
上季度,我从一家 B2B SaaS 客户那里拉出 2,400 个候选关键词,跑完五道筛选,最终只针对其中 87 个写文章。四个月后,这 87 个里有 22 个冲进了 Google 搜索结果前 10。其余 65 个还在爬,但大多在往上走。淘汰掉的 2,313 个并不是"烂词"——它们只是没活过这条漏斗。
关键从来不是找到低竞争关键词。Ahrefs 免费工具一下午就能给你一千个。关键是找到那些搜索者真的愿意掏钱的低竞争关键词。这是完全不同的问题,需要完全不同的筛选链。
KD 分数为什么是个陷阱
关键词难度(KD, Keyword Difficulty)是"这个词有多难做上去"最常用的代理指标,也是最容易被过度信任的。
Ahrefs 的 KD 来自排名前 10 的页面引用域名数(Referring Domains, RDs)的中位数:KD 10 大约对应 10 个 RD,KD 40 大约 60+,KD 80 以上 200+。Semrush 的 KD 用了另一套模型——页面权重加上 SERP 特征、再加点击预估——同一个关键词通常会比 Ahrefs 偏高。这两套系统是从不同角度看同一片竞争格局,谁也没告诉你,搜索的人到底想不想买你卖的东西。
这个差距才是整场游戏的关键。我曾经在一次推广里栽过跟头:目标词是"email automation best practices"(邮件自动化最佳实践),KD 22,搜索量不错,排名也容易拿。六个月写稿之后,流量数据漂亮极了,转化是零。搜索意图是信息型,不是商业型。仪表盘上的访问者数,一个客户都没带来。
KD 告诉你需要多少外链才能挤进前 10。它完全没告诉你,打这个词的人是谁。
5 步筛选法
我把每个候选关键词按顺序过 5 道筛子,任何一道不过就立刻停。漏斗故意做得狠。
第 1 筛——KD 低于 20(Ahrefs 或 Semrush)
对,这一步只看 KD。但它只是个门槛,不是全部。
我把上限卡在 20,是因为这正好对应两个工具的"易"(Easy)区间——Ahrefs 的 KD 11-20 大致需要 11-20 个引用域名。全新域名(DR, Domain Rating, 域名评分低于 20)我会卡到 0-15。绝对数字不重要,前后一致才重要——同一份清单里混用 Ahrefs 和 Semrush 的 KD,会悄悄重复算一部分词、漏掉另一部分。
操作很简单:超过上限的直接删。别自己劝自己。
第 2 筛——月搜索量在 50 到 1,000 之间
50 以下太薄,做不成单页内容;1,000 以上几乎一定拥挤,SERP 上一眼能看出来。50-1,000 这个区间,是"够长尾但没死透"的黄金地带。
这一步直接把客户的清单从 2,400 砍到 480。砍掉的那 80%,就是你不再被工具里的数字游戏牵着走的结果。
一个提醒:2026 年的搜索量数据噪声很大,别迷信绝对值。把这个区间当合理性检查,别当精密仪器。
第 3 筛——首页至少有一个弱结果
这一步是大多数人跳过的,也是最关键的一步。
手动打开 SERP(Search Engine Results Page, 搜索引擎结果页)。在首页前十里,找以下任意一个信号:
- 一个 DR 低于 30 的页面排进了前 10
- 一条论坛贴(Reddit、Quora、Stack Exchange)挤进了前 5
- 一篇内容薄弱的页面——不到 300 字,或者一串内链列表,或者明显是 AI 生成的废话
- 一篇 2021 年甚至更老的过时文章
- 一个几乎没外链的页面(Ahrefs 或 Semrush 上一查便知)
如果首页十条全是 DR 70+ 的网站、内容扎实、外链强,那这扇门是关着的,再用 Gemini 也敲不开。
只要首页有一个弱结果,SERP 就在告诉你:Google 自己也还没找到最满意的答案。这就是你的窗口。
举一个这次推广里的真实例子:关键词"best CRM for solo consultants"(独立顾问最佳 CRM 系统),Ahrefs KD 18,月搜索量约 320。SERP 上去看,#4 是一条 2019 年的 Quora 问答,#7 是 DR 22 博客上一篇薄弱的联盟营销清单文。前三名确实是大站,但整页有明显弱点。我们发了一篇 2,400 字的对比长文,三个月后,这个帖稳定在 #5。
第 4 筛——查询里包含购买意图的修饰词
哪怕 KD 15、月搜索 200,如果搜索者只是在找免费信息,这个词也白做。
查询里至少要包含以下其中一类动词或模式:
- 购买类:"buy"(买)、"order"(下单)、"pricing"(定价)、"cost"(费用)、"cheap"(便宜)
- 比较类:"vs"、"versus"、"compared to"(对比)、"alternative to"(替代)、"alternatives"(替代品)
- 评估类:"best"(最好)、"top"(顶级)、"review"(评测)、"reviews"(评测)、"worth it"(值不值)
- 行动类:"free trial"(免费试用)、"demo"(演示)、"sign up"(注册)、"download"(下载)、"for [具体场景]"
不带任何这类模式的查询基本都是信息型。"What is a CRM"或"How does email automation work"可以拿来当漏斗顶端的科普内容,但它们不带来收入。
这一步把 480 砍到 280。低搜索量、低 KD 的查询里,大约 40% 是搜定义的人。别给他们写商业稿。
第 5 筛——Gemini 判断它落在你的产品楔子里
前 4 筛是机械的。第 5 筛是瓶颈,也是唯一需要 LLM(Large Language Model, 大语言模型)的一步。
前 4 筛活下来的词(我的案例里约 280 个)我按 100 一组批给 Gemini 2.5 Flash。模型读每个查询,判断主题是否落在客户的产品楔子(wedge)里,然后输出结构化标签。这位 SaaS 客户的产品楔子我写得很窄:"面向独立顾问和 20 人以下小机构的 B2B 销售管道软件"——故意写窄,因为"窄"才是这步的核心。
Prompt 大致长这样:
text你正在为一家 B2B SaaS 公司分类搜索查询。
产品楔子:面向独立顾问和 20 人以下小机构(under 20 employees)的 B2B 销售管道软件。
对下面每个查询,判断:
1. 背后主题是否落在产品楔子里?(yes / no / maybe)
2. 搜索者最可能的意图?(informational 信息型 / commercial 商业型 / transactional 交易型)
3. 置信度,0 到 1。
只输出 JSON(JavaScript Object Notation, 一种结构化数据格式),匹配以下 schema:
{
"query": "string",
"in_wedge": "yes" | "no" | "maybe",
"intent": "informational" | "commercial" | "transactional",
"confidence": number
}
查询列表:
1. best CRM for solo consultants
2. how to track sales pipeline excel
3. ...Gemini 标 in_wedge: no 的全部删,maybe 当作临界。intent 字段要和第 4 筛交叉验证——Gemini 说信息型,但查询里有购买修饰词,以修饰词为准,因为 SERP 反映的是修饰词。
280 个候选,首轮 Gemini 跑完剩 140。我把 maybe 那批重新喂了一次,这次把楔子描述写得更细,救回来 40 个,凑到 100。再人工复核 100 个,最后 87 个进清单。
confidence 分数才是真正可调的旋钮。临界查询上 Gemini 给 confidence: 0.4,通常都不对——但模型很少"自信地错"。盯分数,别只盯标签。
漏斗算术
把整条链的数字摆开,方便你校准自己的清单:
| 阶段 | 筛子 | 剩余 | 累计淘汰 |
|---|---|---|---|
| 0 | 原始候选 | 2,400 | — |
| 1 | KD < 20 | 1,200 | -50% |
| 2 | 搜索量 50-1,000 | 480 | -80% |
| 3 | 弱 SERP 结果 | 280 | -88% |
| 4 | 购买意图修饰词 | 140 | -94% |
| 5 | Gemini 楔子分类 | 100 → 87 | -96% |
2,400 到 87,转化率约 3.6%。看着狠,但 87 个代表的是:排名难度低、有真实需求、当前竞争弱、购买意图明确、产品契合度被验证过的关键词。你读到的绝大多数 SEO 文章都在教人追搜索量;几乎没人告诉你,把 96% 的候选扔掉才是正解。这就是重点。
四个月后,87 个里 22 个进前 10,31 个在第二页,34 个还在中段或以下。没有任何一个掉出前 50。砍掉的 2,313 个不是失败,是"一开始就被正确识别为不值得花时间"。
两个值得提醒的地方
两件事如果当时做到,这次推广还能更好。
第一,搜索量这一筛最脆。2026 年的搜索量数据比三年前嘈杂得多,部分原因是 AI 概览(AI Overviews)吃掉了大量漏斗顶端的查询。如果下个季度重跑这条漏斗,我预期 480 这个数字会变,而且变的方向不一定和 Search Console 里看到的一致。用区间,别用绝对数。
第二,Gemini 的 in_wedge 标签质量,只和你的楔子描述一样好。第一次跑的时候,楔子我写的是"B2B SaaS for small businesses"(面向小企业的 B2B SaaS)——太宽,模型几乎全说 yes。换成"面向独立顾问和 20 人以下小机构的 B2B 销售管道软件"之后,yes 集合直接砍半,最终 87 个锐利得多。楔子写得越窄,Gemini 的输出越有用。
96% 的淘汰率听起来像漏斗坏了。其实它是在工作。剩下的 96% 写六个月,产出的是能排名但没转化的内容;这 87 个,才值得再写六个月。