Claude Computer Use 代理:每天监控前 20 个关键词排名,有变化就 Slack 告警
目录
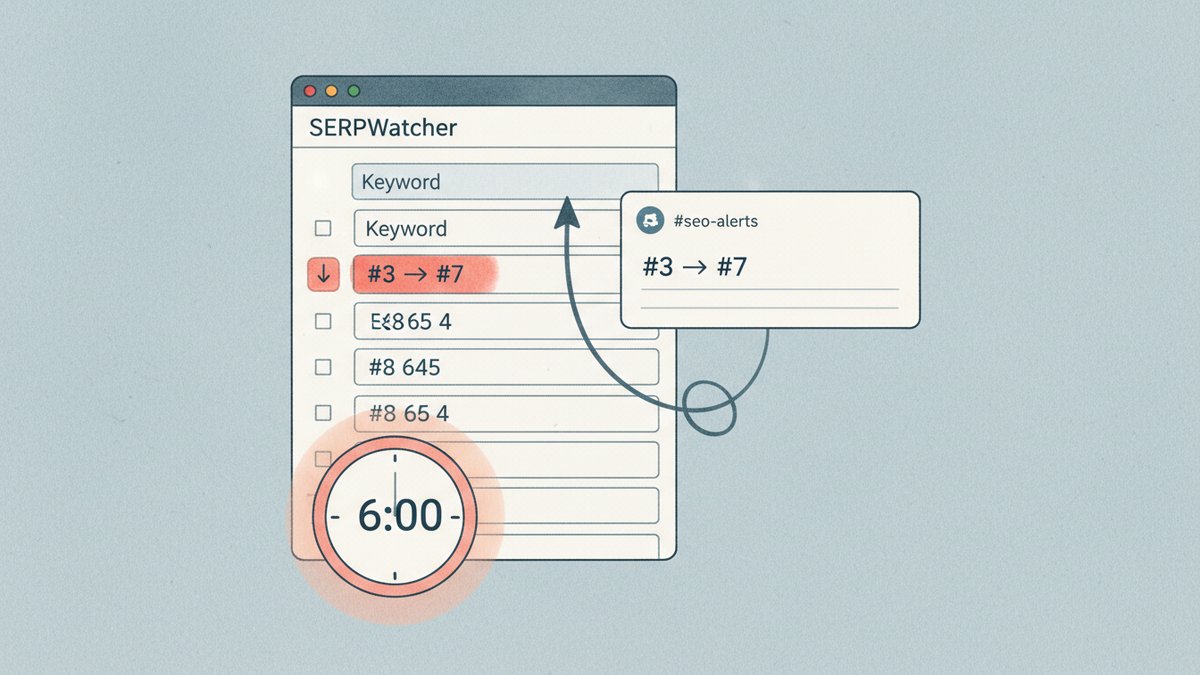
上周二早上 7:14,我的 Slack 弹了一条消息:"关键词 'best running shoes for flat feet' 一夜之间从第 3 名掉到第 7 名。"这次排名下滑发生在凌晨 1 点到 5 点之间——正好是 Google Helpful Content(有用内容)更新的发布窗口期。比起那些周一早上才会去看排名变化的同行,我整整多了两个小时的反应时间。这条预警就是我写这篇文章的原因,也是我后来在自家项目和客户项目里都跑 Claude Computer Use 代理的原因。
Claude Computer Use(Anthropic 让 Claude 真正驱动浏览器——点击、输入、读截图的能力)天生就是为这种任务设计的:短小、重复、依赖视觉的检查,偏偏没有干净的 API。关键词排名监控就是它的完美匹配场景。大部分 SEO 工具要么根本没有公开 API,要么 API 限速严格到日常监控根本没法用。所以我干脆不写爬虫,让 Claude 像人一样使用工具。
下面就是完整的搭建过程。第一次做大概要 90 分钟,稳态之后每天的运行成本大约是 0.04 美元。它已经帮我抓到过好几次排名下滑——要是没有这个监控,我可能要过几周才会发现。
我们到底在搭什么
一个小型定时任务,做这几件事:
- 在 headless 浏览器里打开一个排名追踪工具的仪表盘(SERPWatcher、Ahrefs,甚至免费的 SERP 抓取工具都行)
- 读出某个域名下前 20 个关键词的当前排名
- 和昨天的快照做对比
- 把排名变动超过 2 位的关键词发到 Slack 频道
完全不用写直接对接 SERP 的代码,也不用跟排名工具的 API 较劲。这个代理就像你本人一样去操作浏览器,只不过是在你还没起床的早上 6 点。
第一步——选一个 Claude 真的能"看到"的排名追踪工具
Computer Use 是靠视觉工作的。选哪个工具的关键,是要看它的数据是否一眼可见,而不是藏在 5 层点击之后。
我的短名单,按对 Computer Use 的友好度排:
- SERPWatcher (Mangools) —— 干净的单一页面仪表盘,20 个关键词的排名全部在首屏可见,每月约 19 美元能跟踪 100 个关键词。这就是我自己在用的。
- Ahrefs Rank Tracker —— 能用,但数据被切到了多个标签页。Claude 得逐个点进每个关键词才能看到位置。每个关键词要多花 3-4 步操作。
- Google Search Console + 自建前端 —— 数据最准,但你得自己搭一个仪表盘。第一次做的话不建议。
- 免费的 SERP 抓取工具,比如 SERPapi 的界面,或者 Google Sheets 里的 =GOOGLEFINANCE 风格的小技巧 —— 用来做 PoC(Proof of Concept,概念验证)可以。别交付给客户。
如果你已经在用 Ahrefs 或 Semrush,不想再开一个订阅,Ahrefs 也能跑。但每天的运行成本会从 0.04 美元涨到接近 0.10 美元。SERPWatcher 之所以更便宜,是因为代理完成任务需要的步数更少。
第二步——配置 Slack 的 Incoming Webhook
免费的,4 分钟搞定:
- 打开 api.slack.com/apps,新建一个 app,选定工作区
- 启用 "Incoming Webhooks",点 "Add New Webhook to Workspace"
- 选择要发消息的频道(我用的是
#seo-alerts) - 复制 webhook URL——长得像
https://hooks.slack.com/services/T.../B.../...
把这个 URL 存到 .env 文件里,不要写进 prompt。后面发 Slack 那一步会用到它。
我用的消息格式:
json{
"channel": "#seo-alerts",
"text": "*SEO Alert — *\n3 keywords moved more than 2 positions overnight:\n• `best running shoes for flat feet`: #3 → #7 ↓4\n• `marathon training plan 16 weeks`: #5 → #8 ↓3\n• `running shoes supination`: #12 → #9 ↑3"
} 纯文本,不用 Block Kit。Block Kit 会让 Computer Use 多花好几步去操作。保持简单就好。
第三步——能真正驱动仪表盘的 Computer Use Prompt
这一步我试了三次才写对。Computer Use 的 prompt 需要具备普通 Claude prompt 没有的三个要素:明确的停止条件、清晰的返回格式、以及 UI 读不到时的兜底逻辑。
这是我在用的角色块(这是我直接拼在 prompt 开头的原文):
You are an SEO rank-tracking agent. You will be given a URL to a
rank tracking dashboard, login credentials, a list of 20 target
keywords, and yesterday's positions as a JSON object.
Your job:
1. Log in to the dashboard
2. Navigate to the rank tracking view for the target domain
3. Read the current position for each of the 20 keywords
4. Compare against yesterday's positions
5. Identify any keyword whose position changed by more than 2 places
(in either direction)
6. Return a JSON object with: { "changes": [ { "keyword": str,
"old": int, "new": int, "delta": int } ], "unchanged_count": int }
Stopping condition: you have a complete JSON object, OR you have
failed 3 times to read a value (in which case set that keyword's
position to null and continue).
Hard rules:
- Do not click on ads, do not navigate away from the dashboard
- If a value is unreadable (overlapping chart, hidden behind a
tooltip), say so explicitly and move on
- Never invent positions. null is always better than a guess.
- Return ONLY the JSON object, no prose"Stopping condition" 这一行是最关键的。没它的话,Claude 会为了找缺失的数据一直点"下一页",原本 0.04 美元一次的任务会变成 0.40 美元。加上之后,代理稳定在 8-14 步完成任务。
"Never invent positions" 是第二重要的规则。有一次 Claude 信心满满地报了一个第 4 名,结果仪表盘上其实是第 11 名。模型就是想"有用"一点。我必须把这种"想要有用"的冲动给管住。
第四步——封装一个调用 Anthropic API 的运行器
Computer Use 的循环其实就是标准的 Anthropic API,只是 tools 数组配置成 computer actions。Anthropic 在 github.com/anthropics/anthropic-quickstarts 提供了参考代码——把 computer-use-demo 这个仓库 clone 下来,然后改一下循环,让它:
- 从环境变量读取凭据(仪表盘登录信息、Slack webhook)
- 把昨天的快照存到一个小 JSON 文件(
/data/rankings-<date>.json) - 代理返回后,把今天的快照写到新文件
- 如果 changes 数组不为空,就 POST 到 Slack
用 Sonnet 4 跑 SERPWatcher 的成本:每次大约 8 步 × 每步约 3,500 tokens = 每次约 28K tokens。按 $3 / $15 每百万 tokens 算,每次日常检查大约 0.03-0.05 美元。可以忽略不计。
第五步——定时调度
我用 GitHub Actions 的 cron job 在 UTC 时间早上 6 点跑。这个 action 会:
- 启动一个 Ubuntu runner
- 安装 Playwright(Claude 用来驱动浏览器的工具)
- 运行 Python 运行器
- 把今天的快照 commit 回仓库
- 发到 Slack
几个坑:
- 不要在 UTC 午夜跑——那是大部分排名追踪工具刷新的时间,读数会很不稳定。UTC 早上 6 点在刷新之后、人起床之前,刚好。
- 在仓库里保留 7 天的滚动快照窗口——做 diff 只需要昨天的数据,但你第一次调试的时候肯定要看历史。
- 给代理设一个 5 分钟的硬超时。如果真的触发了超时,job 应该发一条 Slack 说"rank check failed at
第六步——定义"排名有变化"的判定标准
这是区分"有用告警"和"噪音告警"的关键。我的第一版是只要排名动就发,一天能收到 14 条 Slack。不到一周我就把它关了。
调了两个月后我定下来的阈值:
- 排名下降 ≥ 3 位 → 红色告警,立即发 Slack
- 排名上升 ≥ 5 位 → 蓝色告警,每天早上 8 点汇总发送(不是即时)
- 排名下降 1-2 位 → 忽略,这就是噪音
- 排名上升 1-4 位 → 忽略,SERP(Search Engine Results Page,搜索引擎结果页)本身的浮动比想象的大,特别是后半页
"下降 3 位"的阈值基本能抓到所有真实事件(算法更新、竞品动作、技术 SEO 故障)。"上升 5 位"的阈值能抓到值得庆祝的胜利,而不是 SERP 的随机重排。
如果让我重新开始,我会怎么做不同
我低估了截图分辨率的影响。第一版代理在高 DPI 的 MacBook 截图上有 30% 的概率失败——SERPWatcher 的数字太小,识别不稳。后来我切到 Linux 容器、固定 1280×720 的视口,失败率降到了 5% 以下。
如果从零开始,不要先调 prompt。先把浏览器环境搞稳定。一张像素清晰的仪表盘截图是一切的地基。没有这个地基,prompt 写得再漂亮也没用。
还有一点——前面那一周我会直接跳过 Computer Use 代理,先用 Claude API 加上排名追踪工具的 导出功能。大部分付费工具都自带"Send to Slack"或者"Email weekly report"按钮。先用这个。让告警先跑起来。让自己习惯收到告警。等阈值逻辑和频道频率都验证好了,再用 Computer Use 去覆盖那些导出功能做不到的部分(自定义阈值、自定义 diff 格式、还有"只对下跌告警"这种大部分工具都不提供的逻辑)。
还有一句值得说的话
如果你的排名追踪工具有正经 API,用 Computer Use 反而是杀鸡用牛刀。大部分工具要么没 API,要么把 API 藏在企业版后面。我做这个工作流的根本原因是,2024 年我试了四款排名追踪工具,三款根本就没 API。Computer Use 在"仪表盘就是唯一 API"的场景里,反而是阻力最小的路径。
如果 Anthropic 后续发布了更完善的结构化工具调用能力(我估计会),我大概率会改写成对接排名工具正经 API 的版本。在那之前,这个代理是我能找到的最便宜的可用方案,一条告警省下的时间就已经把开发成本赚回来了——那一次抓到的关键词下滑,是真的被我修回来了。