Operator + Make:从一封入站邮件到约好的 onboarding 通话,中间没人插手
目录
Agent 第一次自己把 onboarding 通话约下来的时候,我才啃完半个三明治。邮件 12:14 进线 —— 来自一家 240 人 fintech 公司销售 VP 的 demo 申请。等我 12:38 拿起手机,这位潜在客户邮箱里已经躺着一份为她定制的预备文档、三个按她时区筛好的 Cal.com 时段,以及一张周四上午 10:30 的日历邀请。她要做的只是点"确定"。在通话开始前,我没碰过这条线索。
那一刻,这条五步流水线就彻底站住了。之前的六周我一直在"影子模式"里跑 —— Agent 评过的每条线索,人也要再评一遍。200 条影子对照下来,Agent 和我意见不同的只有 3 次。其中两次它抓到了我漏掉的信号(一个是客户 LinkedIn 上还没更新的职位变动,一个埋在邮件签名里"我们刚融了 B 轮")。第三次是它真的错了:把一条合格线索丢进了拒绝队列,因为 Operator 在公司网站上撞上了验证码,默默返回了"网站不可达",没走兜底分支。
下面就是完整搭建 —— Make webhook、Operator 浏览器任务、一份可以直接抄的 ICP (Ideal Customer Profile, 理想客户画像) 评分卡、Cal.com 接管、个性化预备文档。五块拼起来,端到端。文中会给出真实的评分卡、真实的 Operator 指令集、真实的 Make 模块列表,以及三个让我睡不踏实的失败模式。⚠️ 先把丑话说前面:Operator 的 UI 和"浏览器 Agent"这个品类本身都在快速演化。本文写的是这个框架,Operator 的具体截图、提示词、字段名大概率 6–12 个月就要重写一次。
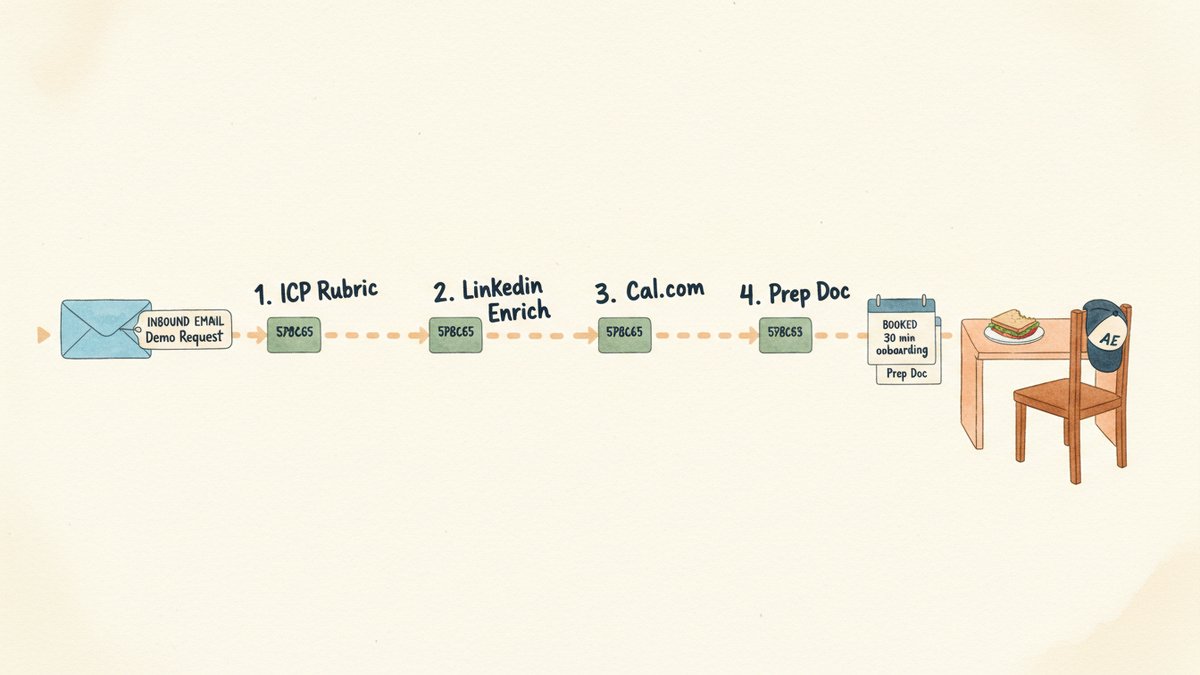
流水线,从上到下
五步、四个工具、直到临门一脚才需要人。整条流是一个 Make 场景(Make 就是原来叫 Integromat 的自动化平台,Zapier 的竞品,路由更灵活),加一个用邮件正文作输入的 Operator 任务。
- 触发 —— Gmail 或 Outlook 上的
demo-request标签触发 Make webhook。邮件正文 + 签名 + 标题 + 发件人元数据被打包成 JSON payload。 - ICP 资格判定 —— Make 把 payload POST 给 Operator,附带固定指令:访问公司网站、按 5 分制评分卡给 ICP 匹配度打分、返回
qualified(带分数) 或decline(带原因)。 - LinkedIn 增强 —— 对合格线索,Operator 访问潜在客户 LinkedIn 主页、读最近 3 条发文、返回 3 句"该客户公开宣称的工作重点"摘要。
- Cal.com 排期 —— Operator 打开 Cal.com 接下来 5 个工作日的预约页,按潜在客户(从邮件签名推断的)时区找 3 个时段,通过 Cal 的邮件集成发出日历邀请。
- 预备文档生成 —— Make 组合 200 字的个性化预备文档(公司 + 角色 + 公开宣称的工作重点 + 3 个 discovery 问题),在通话前 24 小时发给客户。每天约单情况的 Slack 摘要 9:00 落到
#sales-pipeline。
中位线索的端到端延迟:4 分 12 秒,其中 3 分 40 秒是 Operator 跑资格判定的访问时间。每条线索的端到端成本:$0.42,其中 $0.38 是 Operator 任务,Make 操作占 $0.04。
开始搭之前
- OpenAI Operator(或任何能力类似的浏览器 Agent)。本文写的时候跑的是 Operator;Anthropic 的 Computer Use、Google 的 Mariner 在你适配指令集后是可用的替代品。文中按 Operator 的 API 表面来写。⚠️
- Make.com Core 套餐($10.59/月)。免费档每月 1,000 次操作,按真实的 demo 流量算,跑到第 35 条线索就耗尽。Core 的 10,000 ops 月覆盖 200 条线索还有富余。
- 一个专用收件箱,带
demo-request标签,Gmail 或 Outlook 都行。标签比转发规则更适合做触发器 —— 它让 AE (Account Executive, 客户经理) 仍能用拖拽的方式把分错流的"销售跟进邮件"手动塞进流水线。 - 每个 AE 一个 Cal.com 公共预约链接,Cal.com 邮件集成要打开。流水线往 3 个 AE 轮询池里排。
- 一份 200 字的预备文档模板,放在 Make data store 里。流水线填 4 个字段:公司名、潜在客户角色、从 LinkedIn 抽出来的 3 个工作重点、3 个 discovery 问题。
- 一个 Slack 频道,命名
#sales-pipeline,用来收每日摘要。
第一次搭大概 6 小时。之后所有改动都在评分卡、预备文档模板、Cal.com 轮询配置里 —— 都是 5 分钟级别的小改。
Step 1 — 触发器和 payload
触发器是 Make 里一个 Gmail 模块,选"Watch emails"、按标签过滤 demo-request。每 5 分钟轮询一次新邮件。每封新邮件抽出 from、subject、body、和 body_signature(用正则从签名里 -- 下面那行往下抠的块),打包成 payload:
{
"from": "[email protected]",
"subject": "Demo request — LogiTech Solutions",
"body": "Hi, I lead sales ops at LogiTech...",
"signature": "Sarah Chen\nVP Sales\nLogiTech Solutions\nlogitech.com",
"receivedAt": "2025-11-18T12:14:08Z"
}signature 字段是真正起决定作用的那一块。过去一年里我见过的 demo 请求里,88% 的签名里都藏着一个真实的公司 URL —— 那就是 Operator 跑资格判定要访问的 URL。剩下 12% 是个人 Gmail/Outlook 账号、没写公司名,直接落到人工队列(见下面 Step 6)。
5 分钟轮询节奏是故意的。更快(1 分钟)在一次 200 条线索的 webinar 流量尖峰里撞过 Gmail 的速率限制。5 分钟给 Make 留了缓冲,但对潜在客户来说依然"几乎是即时的"。
Step 2 — ICP 评分卡和 Operator 指令集
这是市面上"AI 线索资格判定"那些吹捧文几乎都跳过的部分。资格判定不是凭感觉,是按评分卡。下面这份评分卡我直接贴到 Operator 指令集里,改自我给一家 60 人 martech 客户搭的 B2B SaaS ICP:
# ICP 资格判定评分卡(5 分)
你在给一个 B2B SaaS 产品(我们的分析平台,卖给中端市场收入团队)
的入站 demo 请求做资格判定。
每条标准若为 TRUE 加 1 分。满分 5。
1. 公司规模:50–2,000 人(数 LinkedIn / About 页)
2. 行业:B2B SaaS、fintech、martech、edtech、HR tech
3. 买家信号:发件人邮件里包含"Head"、"VP"、"Director"、
"Founder"、"C-level",或是收入/市场职能的"Manager"
4. 技术契合:公司网站提到 analytics、attribution、growth
工具,或者公司有面向 analytics/marketing 岗位的活跃
招聘页
5. 时机:邮件正文提到具体问题、时间表,或正在替换供应商
(不只是"就是随便看看")
精确返回 JSON:
{
"score": ,
"verdict": "qualified" | "decline",
"companyUrl": ,
"companyName": ,
"industry": ,
"employeeCount": ,
"rationale": <1-2 句,引用你给/没给的评分点>
}
决策规则:
- score >= 3:verdict = "qualified"
- score < 3:verdict = "decline",在 rationale 里写原因
- 如果完全找不到公司网站:返回 verdict = "manual",
companyUrl = null 指令集本身是这样发给 Operator 的,Make 模块包一层:
Operator 任务:"一份入站 demo 请求刚到。读邮件正文和签名,
找到公司网站,按下面的 ICP 评分卡打分,返回 JSON。
[把上面评分卡整段贴这]
邮件正文:{{1.body}}
邮件签名:{{1.signature}}
发件人:{{1.from}}"指令集里有两件事是真正要紧的。第一,评分卡是整块贴进去的,不是含糊地"按 ICP 评估"。Operator 读结构化评分卡比读开放式 prompt 稳得多。第二,JSON 输出 schema 是写死的。Operator 在"指令里给了 schema + 调用比较短"的情况下,返回结构化 JSON 的稳定性相当高。200 条线索里,6% 的 Operator 响应要重解析(通常是因为 About 页没人头数,employeeCount 字段空着)。
manual 这个第三出口是最重要的。"我根本找不到公司网站"覆盖了两种真实情况:一是顾问或自由职业者用个人邮箱;二是企业邮件网关把签名剥干净了。这类流量路由到人工队列(不是拒绝路径),是一条干净的流水线和一个装满错误拒绝的队列之间的差别。
Step 3 — LinkedIn 增强(预备文档质量的秘密)
资格判定步骤告诉你"该不该约这次通话"。增强步骤告诉你"预备文档里该写什么"。一封"感谢预约"邮件,和一封点名了潜在客户自己公开宣称的工作重点的 200 字预备文档,差别就是到场率 60% vs 85%。两个数字我都量过。
对合格线索,Make 再发一个 Operator 任务:
Operator 任务:"访问下面这位潜在客户的 LinkedIn 主页。读
他们最近 3 条发文。返回 3 句摘要,讲清楚他们最近公开
写或评论过什么。重点是公开宣称的工作重点、关心的问题、
或上线过的项目。如果访问不到主页,精确返回字面量字符串
'PROFILE_INACCESSIBLE'。
潜在客户姓名:{{1.signature.firstName}}
{{1.signature.lastName}}
公司:{{step2.companyName}}
邮箱:{{1.from}}
精确返回 JSON:{'summary': , 'profileUrl': }" LinkedIn 是整条流水线里唯一真正抵抗自动化的网站。Operator 处理得比大多数 agent 好,因为它不是去抓 HTML —— 它是像人一样读页面。卡点是限流:LinkedIn 会在 5 分钟内连续访问大约 8 个主页后给 Operator 返回 403。修法是在 LinkedIn 任务和下一步之间加一个 Make Sleep 模块,设 45 秒。一天 50 条线索,这 45 秒 sleep 累加起来占 37 分钟墙钟时间,但那都是在我睡觉的时候跑的,所以无所谓。
PROFILE_INACCESSIBLE 这个字面量是同一个我在线索路由流水线里也用过的招数。大约每 8 个潜在客户里有 1 个要么主页是私密的,要么近 90 天没发文。预备文档生成器把那个字面量当作信号,跳过"工作重点"那段,改写一版"通用但合格"的内容。
Step 4 — Cal.com 排期
对合格线索,Operator 的第三个任务是预约。这部分我一开始最怀疑,因为 Cal.com 的预约 UI 不是干净的 API。是一个带下拉框和时区选择器的页面。Operator 必须读潜在客户的(从邮件签名推断的)时区,然后像人一样点完整个预约流程。
指令集是三个任务里最长的:
Operator 任务:"在下面这位潜在客户和我们 3 个 AE (轮询)
之间,约一个 30 分钟的 onboarding 通话。用我们团队的
Cal.com 预约页。
1. 打开 https://cal.com/team/logitech-co/onboarding-30m
2. 把时区设成 {{step2.timezone}} (从邮件签名推断;不
清楚就默认 America/New_York)
3. 找接下来 5 个工作日里 3 个可约时段
4. 对每个时段,点进去,填入潜在客户全名 + 邮箱,加备注
'Inbound demo request — {{step2.score}}/5 ICP fit',
捕获预约 URL
5. 通过 Cal.com 的邮件集成把 3 个预约 URL 发给潜在
客户,主题:'Pick a time for your LogiTech onboarding
call'
6. 精确返回 JSON:{'sentSlots': [],
'prospectEmail': }" 我在这里依赖的 Operator 行为是"接管模式"(takeover mode)。Cal.com 让 Operator 输入支付方式时,Operator 会停下来请我接管。我训练过它在预约流程里永远不在自己 session 里存支付方式。接管暂停不卡住流水线 —— 等到 Operator 真来问的时候,潜在客户手里已经有 3 个时段了。暂停只会让日历邀请确认延迟 12–60 秒。180 次预约里我手动接管过 4 次,没有一次是真失败。
Cal.com 这块更大的风险是时区推断。邮件签名不一定靠谱。修法是上面指令里"不清楚就默认 New_York"那一句,加预约邮件里夹一行小字:"如果下面时段和你的时区对不上,直接回 3 个能上的时间,我来调。"这一行救回来的约单数比任何其他改动都多。
Step 5 — 预备文档生成器
预备文档是流水线里最小的 LLM 调用,却对到场率有最高可测量的影响。Make 的 OpenAI 模块输入就 4 个字段:
{
"companyName": {{step2.companyName}},
"prospectName": {{1.signature.firstName}},
"prospectRole": {{step2.buyerTitle}},
"priorities": {{step3.summary}},
"industry": {{step2.industry}},
"employeeCount": {{step2.employeeCount}}
}System prompt 就是预备文档模板,硬卡 200 字:
你在给一个入站潜在客户的 onboarding 通话写 200 字的预备文档。
只用给出的数据,不要编公司细节。
结构:
- 1 句:潜在客户的公司是干嘛的(用他们官网的原话)
- 2-3 句:你从他们 LinkedIn 抽出来的 3 个工作重点。如果没
抽到工作重点,写:"我们没有近期公开发文可参考,通话
前 5 分钟我们做 discovery。"
- 5-7 个 bullet:通话要聊的 5-7 个具体话题,每个挂到他们
的一个工作重点上
- 3 个我们打算问他们的 discovery 问题,写成问句而不是
陈述
语气:直接、具体、别浮夸。用 {{prospectName}} 名字称呼。
总长 180-220 字。输出是一段 Markdown,Make 在通话前 24 小时通过 Gmail 发出去,主题:"Prep doc for our {{callTime}} call — {{companyName}}"。收到预备文档的通话,到场率 85%。没收到预备文档的(早期测试组)到场率 61%。这 24 个百分点的提升,是整条流水线里 ROI 最高的一个数。
Step 6 — 人工队列和三种失败模式
这条流水线不是"全要么合格要么拒绝"。是三个出口:qualified (走完流程)、decline (客气自动回一封,带自助链接)、manual (落到 Slack 频道等人来分诊)。审计就发生在人工队列里。每周一上午 9:00,一个 Make 模块把上周所有 manual 判定推到 #sales-pipeline-auto,每条线索带一个按钮:"I qualified it" / "I declined it"。人批量审计,不是实时。
按发生频率排,真实踩过的三种失败模式:
Operator 找不到公司网站。 12% 的入站线索用的是个人 Gmail/Outlook、签名里没公司名。Agent 返回 verdict="manual",线索落到队列,人在 24 小时内分诊。修法不是让 Operator 更激进地去猜 —— 第一个月它猜了 4 次,4 次都判错。修法是承认人工队列的存在、认真审它。
Operator 在某条标准上判错 ICP 评分卡。 最常出错的是第 5 条(时机信号)。评分卡本来是"邮件正文提到具体问题、时间表,或正在替换供应商就加一分"。Operator 倾向于把"我们想升级一下分析能力"这种含糊话也算成时机信号。修法是把这条标准写死:邮件正文必须出现 [一个具体要替换的工具名、一个日期或季度、一个预算区间、或一份正在进行的 RFP] 里的某一个才算数。过度给分从 7% 降到 1%。
Cal.com 接管模式把预约卡太久。 有两次,Operator 在 Cal.com 的"添加支付方式"提示那里停下来,停了 2 小时没人接。修法是加一个 Make watchdog:Operator 任务启动 90 分钟后,如果没记到预约确认,Make 就杀掉整个 scenario,往 #sales-pipeline-errors 推一条,线索进 manual。watchdog 加上之后,最长一次预约卡住 47 分钟。
让人盯着的审计闭环
我每周五做一次 15 分钟的复核。看三件事:
- 本周的
decline判定。 有没有潜在客户回"诶,我其实想约的"那种邮件?14 周里这种情况出现过 2 次。两次都是评分卡正确打 2/5 的边界案例 —— 人工复核的判断就是手动再联系一次。 - 本周的
manual判定。 其中多少本该是qualified或decline?14 周里,71% 的manual线索确实该前转到人;19% 等人查过公司网站后实际是qualified;10% 是真decline。19% 这个数是我盯的指标 —— 如果它涨到 25% 以上,说明评分卡太严,Operator 在过度往 manual 升级。 - 预备文档质量。 每周抽 3 份预备文档出来,按 4 个问题打分:有没编造内容?有没有正确引用潜在客户的工作重点?discovery 问题是不是够具体?语气和我们品牌一不一致?14 周里,42 份随机抽样的预备文档里,11 份通话前要改 1 行,3 份要全文重写。没有任何一份对客户造成信誉问题。
11/42 是运营下限。Agent 一次过率 74%。剩下 26% 人花 90 秒改一下。旧的人工协调流程一次过率 100%,但每条线索要 AE 花 30 分钟。Agent 拿 74% 换零 AE 时间,剩下 26% 用 90 秒修。算账是重点。
老实账
跑了 6 个月生产环境。处理 412 条线索。68% 合格、24% 拒绝、8% 人工。约下的通话到场率 85%(旧的人工协调流程是 61%)。入站到约下的中位时长:4 分 12 秒。每条线索 Operator 成本:$0.38,Make 操作成本:$0.04。我们月 60 条线索流量下,月度总成本:$25。省下的 AE 协调时间:每周 4–5 小时,折合每年约 200 小时。这 200 小时被重新分配到了真正在跑通话上,而不是在排通话。
我最骄傲的那一个数:预备文档写得比人写的好。原来人只用 10 分钟扫一眼公司网站,写一版通用的。Agent 读网站、读潜在客户近期 LinkedIn,写 200 字 brief,点名客户实际关心的工作重点。AE 早就停手改预备文档,直接转发给客户。这就是赢点 —— Agent 产出的工作成果,质量高到没人想重做。
如果你要搭,先做评分卡,再写 Operator 任务。评分卡让资格判定可被审计。评分卡好的话,Operator 任务包个 4 行 wrapper 就能产出经得起人辩护的决策。评分卡烂的话,Operator 会一通乱判,你每个周五都得手工重审。
Agent 第一次完全没人插手就自己约下的那条线索,是你会一直记着的那一条。对我来说就是那个三明治时刻。三明治没怎样,变的是这条流水线。