从 100 篇爆款帖子里抽出 8 种钩子模式:NotebookLM 一次跑通
目录
大多数"20 种钩子模式"清单上线就死。写这些清单的人,从来没有连续读完 100 篇帖子、应用一个频率阈值,再看看到底哪些结构真的反复出现。模式通常是泛泛的——"提个问题"、"用个数字"、"讲个故事"——任何领域都能套,等于一个领域都套不住。B2B SaaS 钩子、美妆钩子、金融科技钩子根本不是同一物种。把这三类硬拍扁的清单,等于没给。
更聪明的做法是:把 100 篇 你的 细分领域里已经爆过的帖子,丢给 NotebookLM,让它去找真正重复的结构。NotebookLM 的源约束模式(source-grounded mode)意味着它不会凭空发明结构——每个返回的模式,都对应你这 100 篇文档库里的真实帖子。你拿到的是一份针对你所在领域的分类法,而不是一篇泛泛的清单文。
第一步 — 抓取你所在领域的 100 篇爆款
最快的路径是 Apify(数据抓取平台)。在 Apify 上跑一个像 scraper-engine/linkedin-profile-post-scraper 的爬虫 actor(每 1,000 篇帖子约 1 美元),针对你所在领域的前 10 位创作者抓取。筛选条件:过去 90 天内评论数 > 50、点赞数 > 1,000 的帖子。下载结果后,用一个小脚本转成 .md 文件——每篇一个文件,互动量、作者、日期作为 frontmatter,帖子正文作为内容。NotebookLM 索引 .md 文件干净利落,结构不丢。
没有 Apify 账号的话,30–50 篇手动复制粘贴也够用。快捷方式:打开帖子,全选,粘贴到纯文本文件,存为 001-作者-日期.md。枯燥但管用。
第二步 — NotebookLM 源约束提示词
新建一个笔记本,上传全部 100 个 .md 文件,然后在对话里贴上这一段提示词:
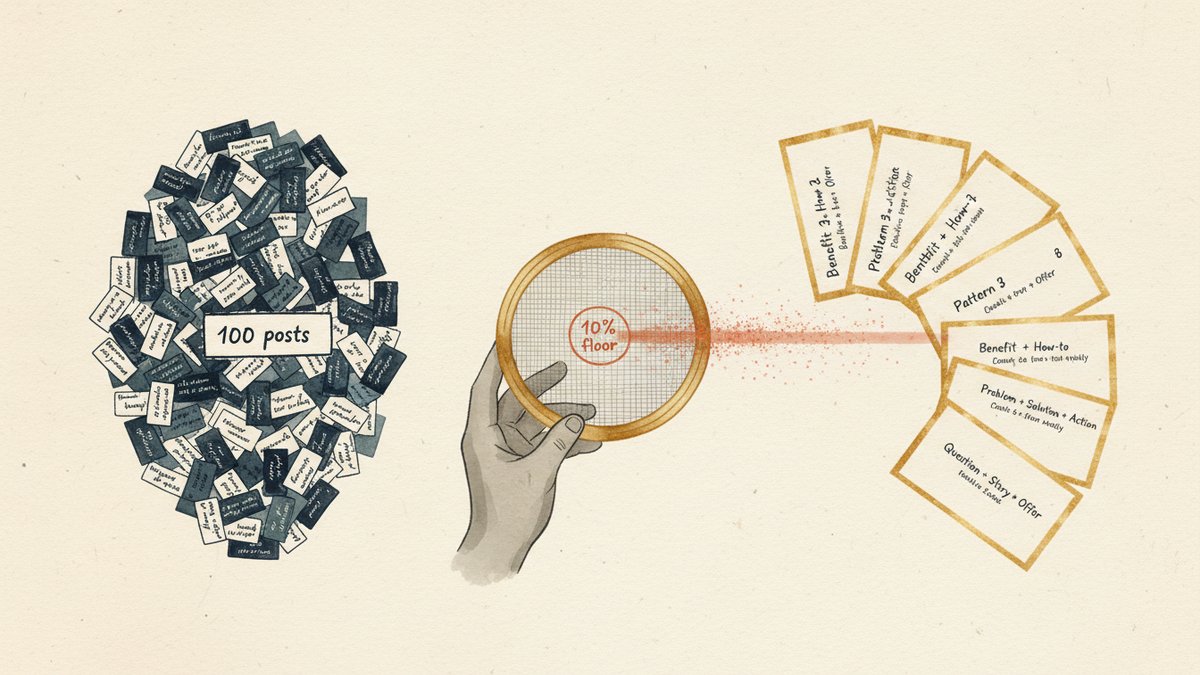
你是一位内容分析师。我上传了 100 篇 B2B AI 工具领域的爆款 LinkedIn 帖子。请通读全部内容,识别出出现频率最高的 8 种钩子结构(即帖子的前 1–3 句)。每个模式请提供:(a) 命名,(b) 带占位符的结构模板,(c) 从语料中引用 1–2 个真实例子的帖子编号,(d) 报告这 100 篇中有多少篇使用该模式。一个模式必须在 100 篇中至少出现 10 篇 才计入——低于这个数,就是噪音。请以 Markdown 表格返回答案。
10% 下限才是关键。没有它,你会拿到 25 个模式,一半是偶然的怪点子。有了它,你拿到的是这个领域的结构性真相。
第三步 — 我从 100 篇 B2B AI 工具 LinkedIn 帖子中抽出的 8 个模式
把上面那段提示词跑在我的 100 篇语料上,结果如下:
| # | 模式 | 模板 | 计数 |
|---|---|---|---|
| 1 | 共同敌人 → 英雄 → 悬念 | "旧的{老路}正在死掉。新的{新路}正在赢。我{赞美它}。为什么?" | 27 |
| 2 | "我{动词}{N}{单位}。这是{框架}。" | "我发了 1,000 封冷邮件。这是 4 行模板。" | 22 |
| 3 | "别再做{X}了。改做{Y}。" | "别用 CRM 了。改用 Excel。" | 17 |
| 4 | 带反向限定的数字清单 | "{N}个{方法},帮你{结果}(且不需要{常见假设})" | 15 |
| 5 | "没人谈论这个" | "没人谈论{细分领域}里的{隐藏变量}。" | 14 |
| 6 | 反共识点名 | "{流行观点}是谎言。真正管用的是这个。" | 13 |
| 7 | 数字型好奇心缺口 | "{X}% 的{受众}{错误行为}。剩下的 {Y}% 这样做。" | 12 |
| 8 | "做{Y}之前我真希望知道这个" | "做{关键节点}之前,我希望自己知道的 5 件事。" | 10 |
8 个模式,每一个都过了 10% 下限。最常见的(模式 1)出现在 27% 的帖子里。最少见的(模式 8)刚好卡在 10%。
第四步 — 怎么用这份分类法
你现在手握一份为 你的 领域量身定制的钩子模式菜单,而不是一本通用文案书里抄来的清单。接下来的 20 篇帖子,要有意识地在这 8 种结构之间轮换。发布时给每篇帖子打上模式编号。3 个月后你会看到你的具体受众奖励哪些模式——领域菜单和你的受众偏好会开始分叉,那才是你真正的优势所在。
那 80 篇泛泛的"钩子公式"文章,让它们待着吧。这个版本才真的合身。